

-
爬虫:一段自动抓取互联网信息的程序
自动访问互联网并提取有价值的数据
查看全部 -
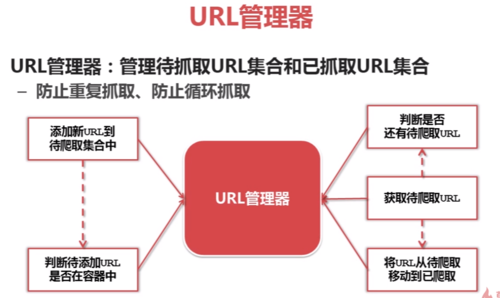
基本的URL管理器:
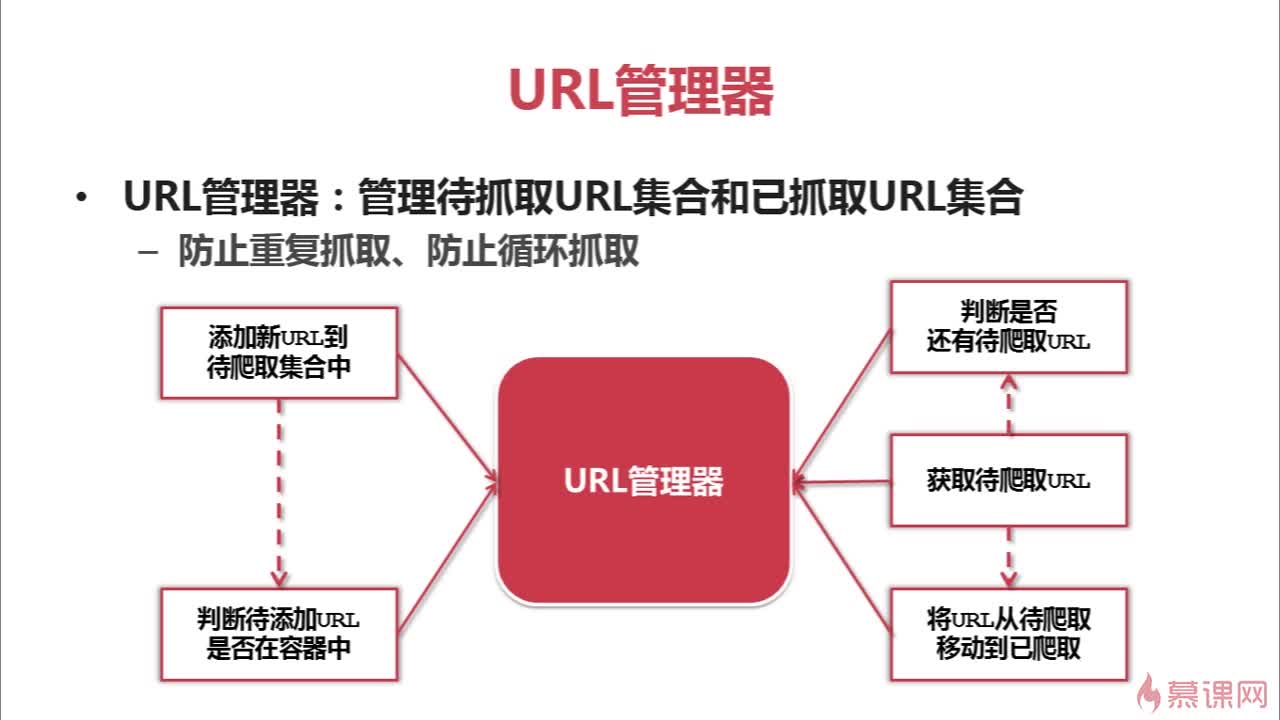 查看全部
查看全部 -
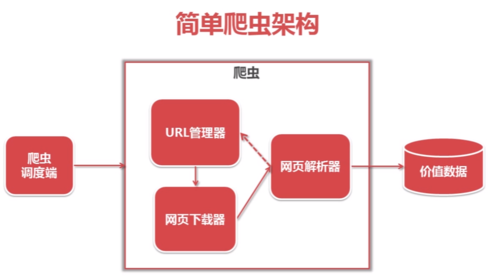
简单爬虫架构:
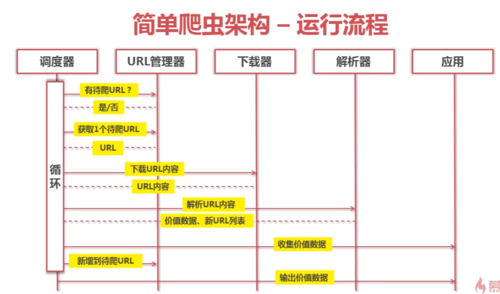 查看全部
查看全部 -
URL管理器:
管理URL
网页下载器
下载URL指定的网页
网页解析器
解析数据
提供URL给URL管理器
查看全部 -
爬虫就是自动访问互联网并且提取数据的程序查看全部
-
URL管理器,网页下载器,网页解析器查看全部
-
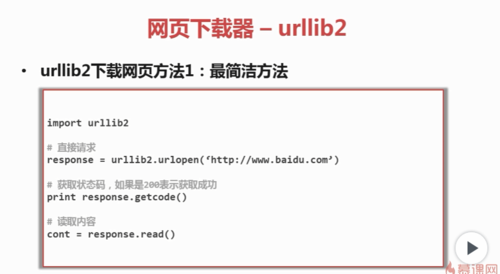
最简洁的方法
查看全部 -
简单爬虫架构的运行流程:
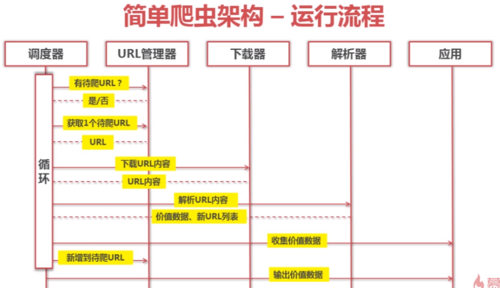 查看全部
查看全部 -
简单爬虫架构:
 查看全部
查看全部 -
URL管理器:
 查看全部
查看全部 -
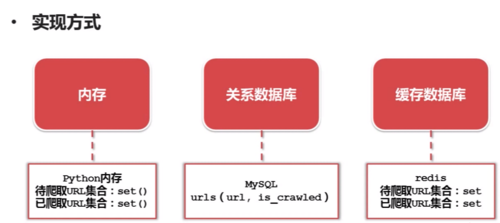
URL管理器的实现方式:
 查看全部
查看全部 -
爬虫的实例:
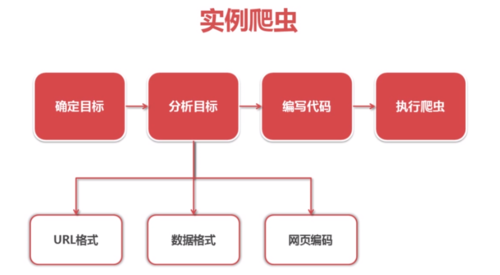
分析目标:
 查看全部
查看全部 -
正则匹配:正则表达式为href=re.compile(r"")
示例1:
print '正则匹配'
link_node = soup.find('a',href=re.compiler(r"ill"))
print link_node.name, link_node['href'], link_node.get_text()
示例2:
print '获取p段落文字'
p_node = soup.find('p',class_="title")
print p_node.name, p_node.get_text()
查看全部 -
网页解析器——BeautifulSoup——语法:
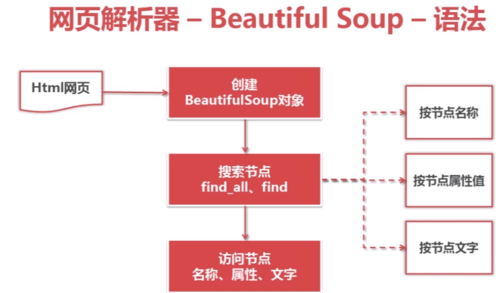
创建Beautiful Soup对象:

搜索节点(find_all,find)

访问节点信息:
 查看全部
查看全部 -
网页解析器—Beautiful Soup—语法
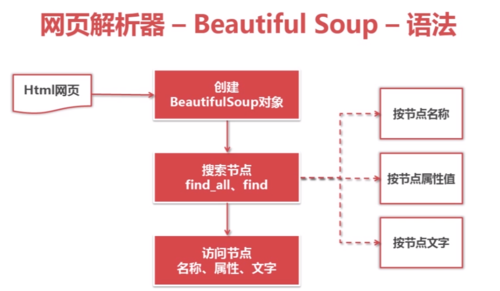 查看全部
查看全部






举报
0/150
提交
取消