

-
运行流程~
查看全部 -
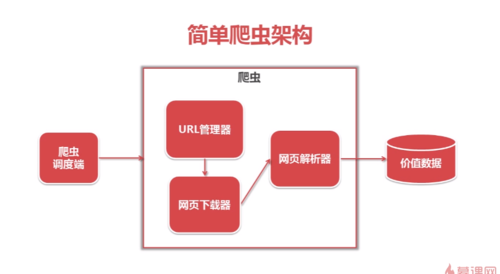
爬虫的基本架构
查看全部 -
j爬虫框架图:
 查看全部
查看全部 -
Python的网页下载器
urllib2(官方基础模块)
requests(第三方包更强大)
查看全部 -
URL管理器之实现方式
大型公司使用“缓存数据库”
小型公司或个人使用“内存”
内存不够用或想要永久保存使用“关系数据库”
查看全部 -
URL管理器
查看全部 -
urllib2 下载网页 方法3
查看全部 -
urllib2 下载网页 方法2
查看全部 -
urllib2 下载网页 方法1
查看全部 -
Python中的两种网页下载器
查看全部 -
网页下载器
查看全部 -
URL管理器的实现方式
查看全部 -
URL管理器的功能
查看全部 -
爬虫架构--运行流程
查看全部 -
简单爬虫架构
查看全部




举报
0/150
提交
取消