

-
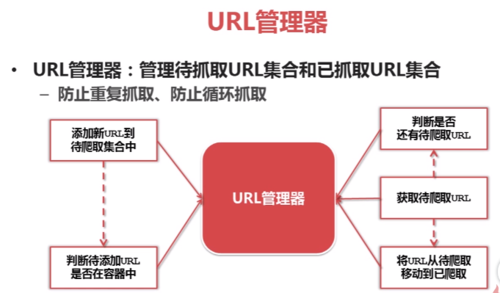
URL管理器作用
 查看全部
查看全部 -
完美。。。
查看全部 -
URL爬取的数据可以储存在python.set()数据格式中
查看全部 -
URL管理器应该实现的基本功能:
查看全部 -
爬虫流程图
查看全部 -
URL管理器:https://baike.baidu.com/item/url/110640?fr=aladdin
查看全部 -
搜索节点(find_all,find)
find_all(name,attrs,string)[名称、属性、文字]
对于它的名称,属性和文字,都可传入一个正则表达式来匹配
'class'后加了'_'的原因:python的关键字有class,bs为了避免冲突,加了一个'_'
查看全部 -
创建BeautifulSoup对象
查看全部 -
Beautiful Soup语法
根据下载好的HTML网页字符串可创建一个BeautifulSoup对象,创建这个对象的同时就会将整个文档字符串下载成一个DOM树
根据这个DOM树我们就可进行各种节点的搜索;搜索节点时,可按照节点名称或节点属性或节点文字进行搜索
查看全部 -
创建BeautifulSoup对象
查看全部 -
网页解析器--结构化解析-DOM
查看全部 -
python的4种网页解析器
查看全部 -
网页解析器
查看全部 -
urllib2下载网页方法3:添加特殊情景的处理器--cookie处理
导入urllib2,cookielib模块
创建cookie容器,存储cookie数据
创建一个opener:然后使用urllib2的HTTPCookieProcessor,以生成的cookie容器作为参数,生成一个header,将header传给urllib2的build_opener()方法来生成一个opener对象
urllib2安装opener:使用urllib2的install_opener增强处理器
使用带有cookie的urllib2访问网页:
查看全部 -
urllib2下载网页方法3:添加特殊情景的处理器
用户登录才能访问的网页,需要添加cookie的处理:HTTPCookieProcessor
需要代理才能访问,需要添加代理的处理:ProxyHandler
网页协议加密的,需要添加处理:HTTPSHandler
网页存在相互跳转关系,需要添加处理:HTTPRedirectHandler
查看全部




举报