

-
 Python正则表达式
查看全部
Python正则表达式
查看全部 -
构造句法规则, 匹配字符, 爬虫抓取查看全部
-
抓取网页中的图片到本地:
抓取网页
import urllib2
req=urllib2.urlopen(url)
buf=req.read()
获取图片地址
抓取图片内容并保存到本地
查看全部 -
re的其他方法
查看全部 -
re的其他方法
查看全部 -
正则表达式语法
查看全部 -
正则表达式匹配前后端
查看全部 -
正则表达式匹配多个字符
查看全部 -
正则表达式匹配单个字符
查看全部 -
ma = re.match(pattern, string, flag)
ma.group()
查看全部 -
re.compile(pattern, re.IGNORECASE) 忽略大小写
pa = re.compile(r'(imooc)')
ma = pa.match('imooc python')
ma.group() =>'imooc'
ma.groups() =>('imooc',)
查看全部 -
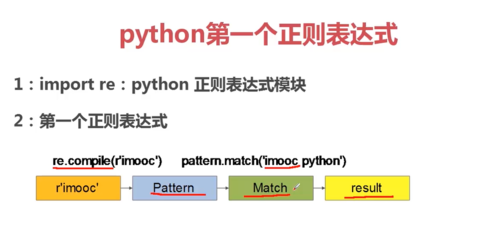
import re
pa = re.compile(r'imooc')
ma = pa.match('imooc python')
ma.group() 返回匹配的字符串或元组
ma.span() 返回匹配位置
ma.string 返回待匹配的字符串
ma.re 返回正则表达式
查看全部 -
正则表达式概念
查看全部 -
课程主要内容
查看全部 -
求解释每一步是什么意思?不明白
i = 0
for url in listurl:
file = open('D:/python/'+str(i)+'.jpg','w')
req = urllib2.urlopen(url)
buf = req.read()
file.write(buf)
i += 1
time.sleep(1)第一步,初始化变量i=1。
第二步,遍历URL列表中的每一个图片的URL
第三步,打开一个文件并返回一个文件对象file,如果文件不存在,则创建文件,w是以只写的方式打开
第四步,用urlopen()方法远程请求url的数据并返回一个文件对象req
第五步,读取文件对象的内容,保存到变量buf
第六步,将内容写到file里面
第七步,i 自增,也就是通过变量自增达到文件名不能相同的目的
第八步,调用time模块的sleep()方法,可以将程序在这一步暂停1秒钟
第九步,关闭文件对象,老师没有写,file.close(),这句尽量要写,否则文件可能有问题,具体自己了解吧
没了~。~
查看全部




举报