

-
课程编译环境: python 2.7
简单爬取网页步骤:
1)分析网页元素
2)使用urllib2打开链接
3)读取链接文本
4)使用re匹配出期望文本内容并分条存入list
5)创建文件定义文件名规则,并将list中的链接逐条用urllib2打开后写入
查看全部 -
. 匹配除 "\n" 之外的任何单个字符。
要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。
[...] 匹配字符集[a-zA-Z0-9]
\d 匹配一个数字字符。等价于 [0-9]。
\D 匹配一个非数字字符。等价于 [^0-9]。
\s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。
\S 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。
\w 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。
\W 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。
[0-9] 匹配任何数字。类似于 [0123456789]
[a-z] 匹配任何小写字母
[A-Z] 匹配任何大写字母
[a-zA-Z0-9] 匹配任何字母及数字
查看全部 -
sum([int(x) for x in info]) 可做到对list式求和
查看全部 -
re—compile--pattern--match--result
查看全部 -
pppppp
查看全部 -
钱钱钱钱钱钱从
查看全部 -
啊啊啊啊啊啊啊啊啊啊啊
查看全部 -
正则表达式查看全部
-
抓网页, 抓图片地址, 抓图片内容并保存本地
查看全部 -
这个分割的功能挺好。
查看全部 -
这里没听懂
查看全部 -
正则表达式:import re
\ 转义字符
. 匹配任意一个字符(处理\n)
[...] 匹配字符集中的任何一个字符
\d/\D 匹配数字/非数字
\s/\S 匹配空白/非空白字符
\w/\W 匹配单词字符[a-zA-Z0-9]/非单词字符
* 匹配前一个字符0次或者无限次
+ 匹配前一个字符1次或者无限次
? 匹配前一个字符0次或者1次
{m}/{m,n} 匹配前一个字符m次或者n次
*?/+??? 匹配模式变为非贪婪(尽可能少匹配字符)
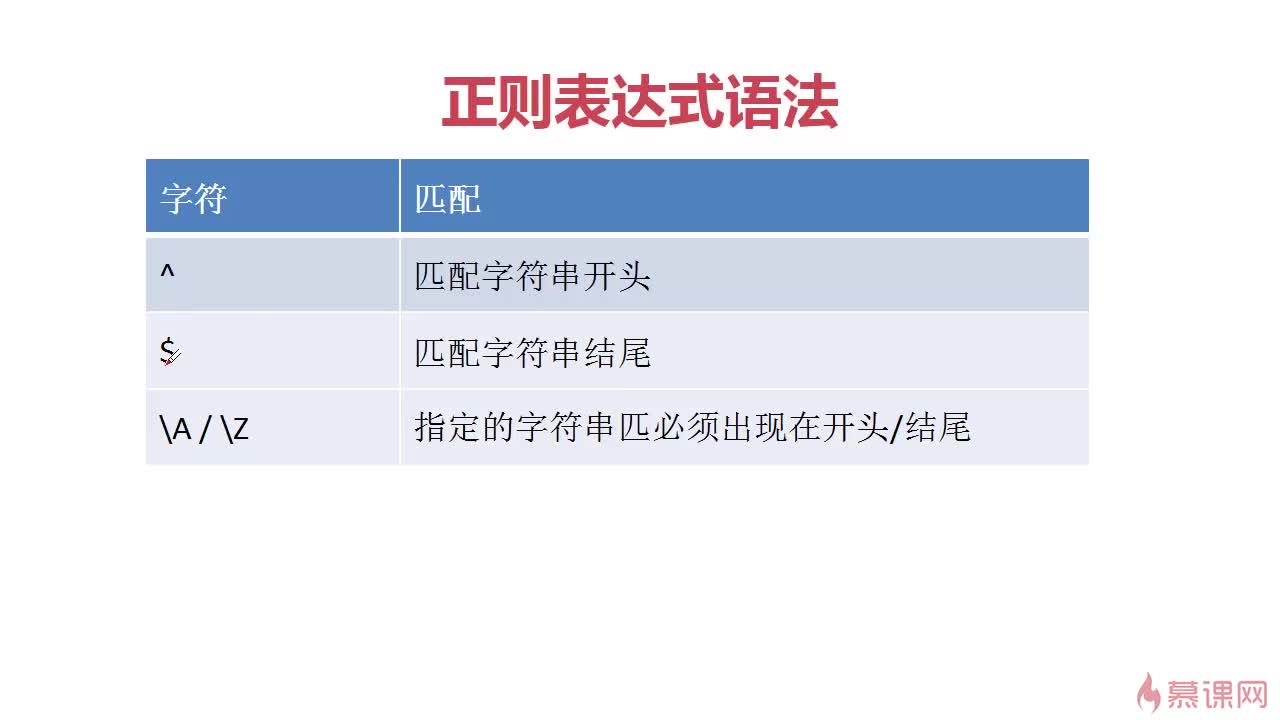
^ 匹配字符串开头
$ 匹配字符串结尾 (在字符串的后边加$)
\A/\Z 指定的字符串
1:search(pattern,string,flags=0) 在一个字符串中查找匹配
2:findall(pattern,string,flags=0) 找到匹配,返回所有匹配部分的列表
3:sub(pattern,repl,string,count=0,flags=0) 将字符串中匹配正则表达式的部分替换为其他值
4:split(pattern,string) 根据匹配分割字符串,返回分割字符串组成的列表
查看全部 -
Urllib:
Python3中将Python2.7的urllib和urllib2两个包合并成了一个urllib库,其主要包括以下模块:
urllib.request 请求模块
urllib.request.urlopen(url)
from urllib import request
request.urlopen()
urlopen返回对象提供方法:
read() , readline() ,readlines() , fileno() , close() :对HTTPResponse类型数据进行操作。
info():返回HTTPMessage对象,表示远程服务器返回的头信息。
getcode():返回Http状态码。
geturl():返回请求的url。
urllib.error 异常处理模块
urllib.parse url解析模块
urllib.robotparser robots.txt解析模块
查看全部 -
search:在一个字符串中查找匹配
findall:找到匹配,返回所有匹配部分的列表
sub:将匹配出来的部分替换为其他值
split:分割字符串,返回分割后的数组
查看全部 -
| 匹配左右任意一个表达式
(ab)括号中表达式作为一个分组
\<number> 引用编号为num的分组匹配到的字符串
(?P<name>)分组起一个别名
(?P=name)引用别名为name的分组匹配字符串
 查看全部
查看全部









举报