
































































 KaliArch ·
KaliArch ·Shell三剑客之awk
1. awk概述
1.1 awk是什么
awk不同于grep的文本搜索与sed工具的文本处理,它更偏向于对文本的格式化处理输出,它不仅仅是一款工具,也是一门解释性语言,其名字来源于它的三位作者的姓氏:Alfred Aho, Peter Weinberger 和 Brian Kernighan,在文本处理功能非常强大,是一款Linux服务器文本报告生成器和格式化文本输出工具。
1.2 为什么用awk
我们日常工作中有很多需要格式化打印输出的需求,更多的是关注列操作时,就可以利用awk工具来进行处理。awk除了是工具也同样是一门语言,其允许用户创建简短的程序来处理自己的需求,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表等。功能非常的强大,相信在掌握了awk,日常运维工作更加方便高效简单。
2. awk的适用场景
- 超大文件处理;
- 输出格式化的文本报表;
- 执行算数运算;
- 执行字符串操作等。
3. awk的处理模式
一般是遍历一个文件中的每一行,然后分别对文件的每一行进行处理。
awk对输入的一行数据进行处理的模式,对整个文件进行重复执行此模式处理,在此说明对输入的一行数据处理的内在机制如下图所示:
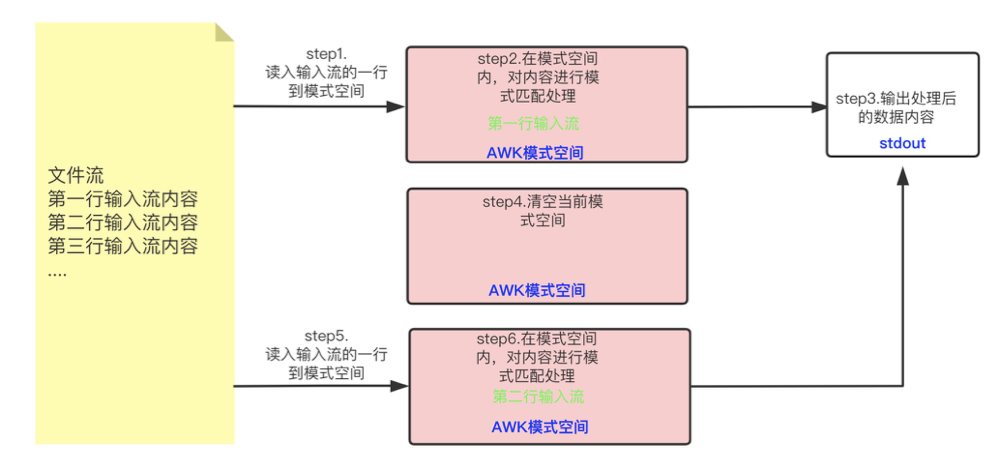
处理过程不断重复,直到到达文件结尾。
- 首先读入文件流的一行到模式空间;
- 在模式空间内,对内容进行模式匹配处理;
- 然后输出处理后的数据内容;
- 清空当前模式空间;
- 读取第二行输入流到模式空间;
- 又开始对模式空间内的第二行输入数据进行处理。
总体可以分为以下三步:
-
读(Read):AWK 从输入流(文件、管道或者标准输入)中读入一行然后将其存入内存中。
-
执行(Execute):对于每一行输入,所有的 AWK 命令按顺序执行。 默认情况下,AWK 命令是针对于每一行输入,但是我们可以将其限制在指定的模式中。
-
重复(Repeate):一直重复上述两个过程直到文件结束。
4. 语法及结构
4.1 语法
Awk 语法格式如下图所示:

awk [options] 'PATTERN {action}' file1,file2
awk 的语法格式主要分为四个字段,options 选项,引号内有模块与动作,以及要处理的文件,接下来让我们详细讲解每一个语法字段,更全面地认识 awk 这个脚本利器。
4.2 程序结构
awk 在引号内有一定的程序结构,主要为以下:
- 开始块(BEGIN BLOCK):
语法:
BEGIN{awk-commands}
开始块就是awk程序启动时执行的代码部分(在处理输入流之前执行),并且在整个过程中只执行一次;
一般情况下,我们在开始块中初始化一些变量。BEGIN是awk的关键字,因此必须要大写。【注:开始块部分是可选,即你的awk程序可以没有开始块部分】
- 主体块(Body Block):
语法:
/pattern/{awk-commands}
针对每一个输入的行都会执行一次主体部分的命令,默认情况下,对于输入的每一行,awk都会执行主体部分的命令,但是我们可以使用/pattern/限制其在指定模式下。
- 结束块(END BLOCK):
语法:
END{awk-commands}
结束块是awk程序结束时执行的代码(在处理完输入流之后执行),END也是awk的关键字,必须大写,与开始块类似,结束块也是可选的。
4.3 awk命令详解
4.3.1 awk 输出
- awk print输出,例如:
print item1,item2...
1.各字段之间逗号隔开,输出时以空白字符分隔;
2.输出的字段可以为字符串或数值,当前记录的字段(如$1)、变量或 awk 的表达式;数值先会转换成字符串然后输出;
3.print 命令后面的 item 可以省略,此时其功能相当于print $0,如果想输出空白,可以使用print "";
例如:
[root@master ~]# awk -F: '{print $1,$NF}' /etc/passwd|column -t
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
sync /bin/sync
- awk printf 输出
printf 命令的使用格式:
printf <format> item1,item2...
要点:
1.其与 print 命令最大区别,printf 需要指定 format,format 必须给出;
2.format 用于指定后面的每个 item 输出格式;
3.printf 语句不会自动打印换行字符\n。
format 格式的指示符都以 % 开头,后跟一个字符:
%c:显示ascall码
%d:%i:十进制整数
%e,%E:科学计数法
%f:浮点数
%s:字符串
%u:无符号整数
%%:显示%自身
修饰符:
#[.#]:第一个#控制显示的宽度:第二个#表示小数点后的精度:
%3.1f
-:左对齐
+:显示数组符号
例如:
[root@master ~]# awk -F: '{printf "Username:%-15s ,Uid:%d\n",$1,$3}' /etc/passwd
Username:root ,Uid:0
Username:bin ,Uid:1
Username:daemon ,Uid:2
Username:adm ,Uid:3
Username:lp ,Uid:4
Username:sync ,Uid:5
Username:shutdown ,Uid:6
4.3.2 awk变量
-
记录变量:
- IFS(input field separator),输入字段分隔符(默认空白)
- OFS(output field separator),输出字段分隔符
- RS(Record separator):输入文本换行符(默认回车)
- ORS:输出文本换行符
-
数据变量
- NR:the number of input records,awk 命令所处理的文件的行数,如果有多个文件,这个数目会将处理的多个文件计数
- NF:number of field,当前记录的 field 个数
{print NF},{print $NF}-
ARGV:数组,保存命令行本身这个字符串
-
ARGC:awk 命令的参数个数
-
FILENAME:awk 命令处理的文件名称
-
ENVIRON:当前 shell 环境变量及其值的关联数组
awk 'BEGIN{print ENVIRON["PATH"]}' -
自定义变量
-v var=value变量名区分大小写,例如:
[root@master ~]# awk -v test="abc" 'BEGIN{print test}' abc [root@master ~]# awk 'BEGIN{var="name";print var}' name
4.3.3 操作符
-
算术运算
- +,-,*,/,^,%。例如:
[root@master ~]# awk 'BEGIN{a=5;b=3;print "a + b =",a+b}' a + b = 8 -
字符串操作
- 无符号操作符,表示字符串连接,例如:
[root@master ~]# awk 'BEGIN { str1="Hello,"; str2="World"; str3 = str1 str2; print str3 }' Hello,World -
赋值操作符:
- =,+=,-=,*=,/=,%=,^=,例如:
[root@master ~]# awk 'BEGIN{a=5;b=6;if(a == b) print "a == b";else print "a!=b"}' a!=b [root@master ~]# awk -F: '{sum+=$3}END{print sum}' /etc/passwd 72349 -
比较操作符:
- >,>=,<,<=,!=,==
-
模式匹配符:
- ~:是否匹配
- !~:是否不匹配
例如:
[root@master ~]# awk -F: '$1~"root"{print $0}' /etc/passwd root:x:0:0:root:/root:/bin/bash -
逻辑操作符:
- && 、 || 、 !,例如:
[root@master ~]# awk 'BEGIN{a=6;if(a > 0 && a <= 6) print "true";else print "false"}' true -
函数调用:
- function_name(argu1,augu2)
-
条件表达式(三元运算):
- selection?if-true-expresssion:if-false-expression
[root@master ~]# awk -F: '{$3>=100?usertype="common user":usertype="sysadmin";printf "%15s:%s\n",$1,usertype}' /etc/passwd root:sysadmin bin:sysadmin daemon:sysadmin adm:sysadmin lp:sysadmin sync:sysadmin shutdown:sysadmin halt:sysadmin
4.3.4 Pattern
- empty:空模式,匹配每一行
- /regular expression/:仅处理能被此处模式匹配到的行,例如;
[root@master ~]# awk -F: '$NF=="/bin/bash"{printf "%15s,%s\n",$NF,$1}' /etc/passwd
/bin/bash,root
- relational expression:关系表达式,结果为“真”有“假”,结果为“真”才会被处理。
Tips:使用模式需要使用双斜线括起来,真:结果为非0值,非空字符串。
[root@master ~]# awk -F: '$3>100{print $1,$3}' /etc/passwd
systemd-network 192
polkitd 999
ceph 167
kube 998
etcd 997
gluster 996
nfsnobody 65534
chrony 995
redis 994
awk -F: '$NF=="/bin/bash"{printf "%15s,%s\n",$NF,$1}' /etc/passwd
awk -F: '$NF~/bash$/{printf "%15s,%s\n",$NF,$1}' /etc/passwd
df -Th|awk '/^\/dev/{print}'
-
line ranges:行范围,制定startline,endline。
[root@master ~]# awk -F: '/10/,/20/{print $1}' /etc/passwd games ftp nobody systemd-network dbus polkitd postfix sshd ceph kube etcd gluster rpc -
BEGIN/END模式
- BEGIN{}:仅在开始处理文本之前执行一次
- END{}:仅在文本处理完成之后执行一次
[root@master ~]# awk -F: 'BEGIN{print "username uid\n--------------------"}{printf "%-15s:%d\n",$1,$3}END{print "-----------------\nend"}' /etc/passwd
username uid
--------------------
root :0
bin :1
daemon :2
adm :3
lp :4
rpc :32
rpcuser :29
nfsnobody :65534
chrony :995
redis :994
-----------------
end
4.3.5 控制语句
- if(condition) {statements},例如:
[root@master ~]# awk -F: '{if($3>100) print $1,$3}' /etc/passwd
systemd-network 192
polkitd 999
ceph 167
kube 998
etcd 997
gluster 996
nfsnobody 65534
chrony 995
redis 994
- if(condition) {statments} [else {statments}],例如:
[root@master ~]# awk -F: '{if($3>100) {printf "Common user:%-15s\n",$1} else {printf "sysadmin user:%-15s\n",$1}}' /etc/passwd
sysadmin user:root
sysadmin user:bin
sysadmin user:daemon
sysadmin user:adm
sysadmin user:lp
sysadmin user:sync
sysadmin user:shutdown
sysadmin user:halt
sysadmin user:mail
sysadmin user:operator
sysadmin user:games
5. 实例
1.统计/etc/fstab文件中每个单词出现的次数,并按从大到小排序
awk '{for(i=1;i<=NF;i++){words[$i]++}}END{for(key in words)print key,words[key]}' /etc/fstab|sort -k2 -nr
awk '{ips[$1]++}END{for(i in ips) print i,ips[i]}' access_nginx.log |column -t|sort -k2 -nr
2.统计/etc/fstab每个文件系统类型出现的次数
awk '!/^#/&&!/^$/{dev[$3]++}END{for(i in dev) print i,dev[i]}' /etc/fstab
3.ping一个域名,输出ping此刻的时间
ping baidu.com|awk '{print $0" "strftime("%Y-%m-%d %H:%M:%S")}'
4.利用netstat监控服务是否正常监听
netstat -lntup|awk 'NR>2{if($4 ~/.*:22/) print $0"yes";exit 0}'
5.统计web服务器日志状态码
awk '$9~"[0-9]"{stat[$9]++}END{for(i in stat) print i,stat[i]}' access_log
6. 注意事项
-
awk同sed命令类似,只不过sed擅长取行,awk命令擅长取列,awk是对文本进行格式化输出,sed更倾向于对文件进行修改; -
对于读入的文件可以根据自己需求对IFS/OFS对输入和输出进行修改;
-
awk非常的强大,但是也是三剑客中最难的一个,其作为一门单独的语言,我们在Shell编程中学习常用的命令及语法就已经足够我们使用。
7. 小结
本章节我们系统性地学习了awk的语法结构及处理模式,其相较于其他文本处理工具,更适合对文本进行格式化输出,我们需要在合适的地方使用,其作为Linux系统上一个非常强大的文本格式输出工具,也是一门语言,后期需要在实践工作中更多地灵活运用,使得脚本编写更加方便。

 2026 imooc.com All Rights Reserved |
2026 imooc.com All Rights Reserved |