
































































 basil_2020 ·
basil_2020 ·使用 Pytesseract 进行简单的验证码识别
在爬虫开发中我们经常会遇到一种反爬虫的手段就是验证码,那么如何才能绕过验证码拿到我们想要的数据呢?这节课我给大家介绍一个破验证码的利器–Pytesseract。
Pytesseract 是 Python 中专门用来识别验证码和字符的常用第三方模块,它是一个根据 Google 开发的 Tesseract 包进行独立封装的产物。由于它在识别验证码方面具有得天独厚的优势,所以经常被爬虫开发程序员用来进行识别验证码。
本节课我们就来使用 pytesseract 进行简单的验证码的识别。
1. 安装 pytesseract
pytesseract 是 Python 的一个 OCR 识别库,可以通过安装这个模块,然后调用相应的方法进行验证码识别。我们只是使用这个模块的一些常用的 API,关于这个模块的其他用途,读者可以根据自己的兴趣爱好自行研究。
pytesseract 是第三方模块,所以需要提前安装才能使用,安装命令如下:
pip install pytesseract
安装过程如下:

2. 第一个例子
我们先使用 pytesseract 进行简单的图片识别。使用图片如下所示:

我们通过调用 image_to_string 方法来进行识别图片中的文字。
# 引进Image和pytesseract模块
try:
from PIL import Image
except ImportError:
import Image
import pytesseract
# 将图片转化成文字
print(pytesseract.image_to_string(Image.open('test.bmp')))
运行结果:
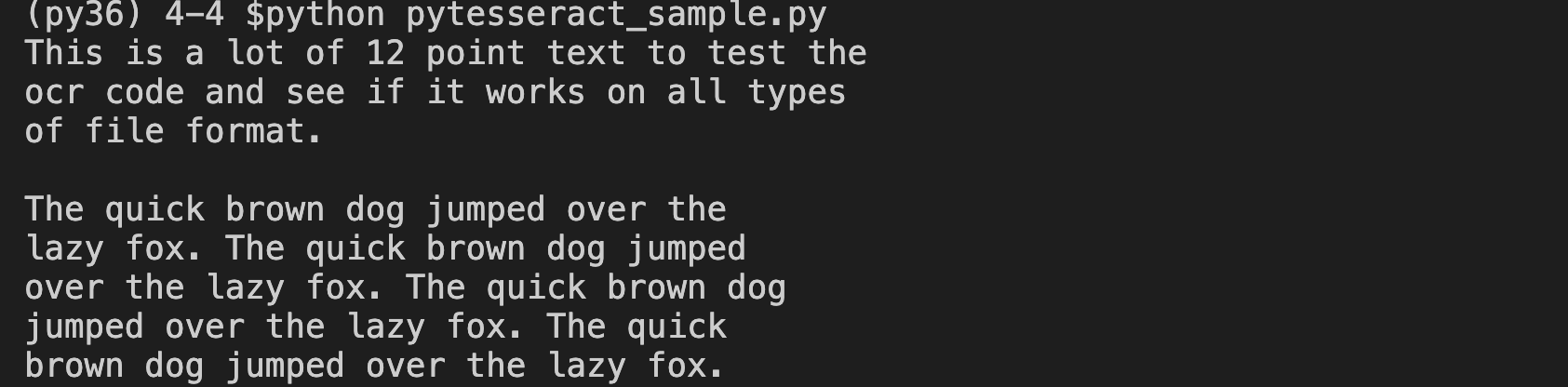
可以看出,pytesseract 能够准确的识别图片的文字。
3. 识别验证码
接下来,我们来尝试使用它来验证验证码。验证码图片如下所示:

代码如下:
import pytesseract
from PIL import Image
im=Image.open('test.jpeg')
#灰度处理
im=im.convert('L')
#设置二值化的阈值
threshold=170
t=[]
for i in range(256):
if i<threshold:
t.append(0)
else:
t.append(1)
#通过表格转换成二进制图片,1的作用是白色,0就是黑色
im=im.point(t,"1")
im.show()
print(pytesseract.image_to_string(im))
#删除冗余字符
print(pytesseract.image_to_string(im)[0:-1])
运行结果:

从运行结果,我们可以看出,虽然我们使用了二值化进行了灰度处理,但是程序仍然不能 100% 的识别验证码,所以,后面我们删除了识别错误产生的小数点,才是最后的结果。
4. 小结
使用 pytesseract 只能识别一些简单的验证码,识别率也不高,需要导入训练好的各种语言包才能提高识别率。另外,如果熟悉机器学习的知识化,根据 pytesseract 提供的方法,可以通过深度学习的算法自己训练一个模型,然后进行识别,可以提高识别的准确度。

 2026 imooc.com All Rights Reserved |
2026 imooc.com All Rights Reserved |