
































































 neadam ·
neadam ·并发容器 ConcurrentHashMap
1. 前言
从本节开始,我们学习新一章内容 —— 并发容器。
本节带领大家认识第一个常用的 Java 并发容器类之 ConcurrentHashMap。
本节先介绍 ConcurrentHashMap 工具类表达的概念和最基本用法,接着通过一个例子为大家解释 ConcurrentHashMap 工具类的使用场合并通过简单的编码实现此场景,最后介绍 ConcurrentHashMap 提供的几个其他常用方法。
下面我们正式开始介绍吧。
2. 概念解释
Concurrent 翻译过来是并发的意思,字面理解它的作用就是提供并发情况下的 HashMap 功能,ConcurrentHashMap 是对 HashMap 的升级,采用了分段加锁而非全局加锁的策略,增强了 HashMap 非线程安全的特征,同时提高了并发度。我们通过一张图片了解一下 ConcurrentHashMap 的逻辑结构。
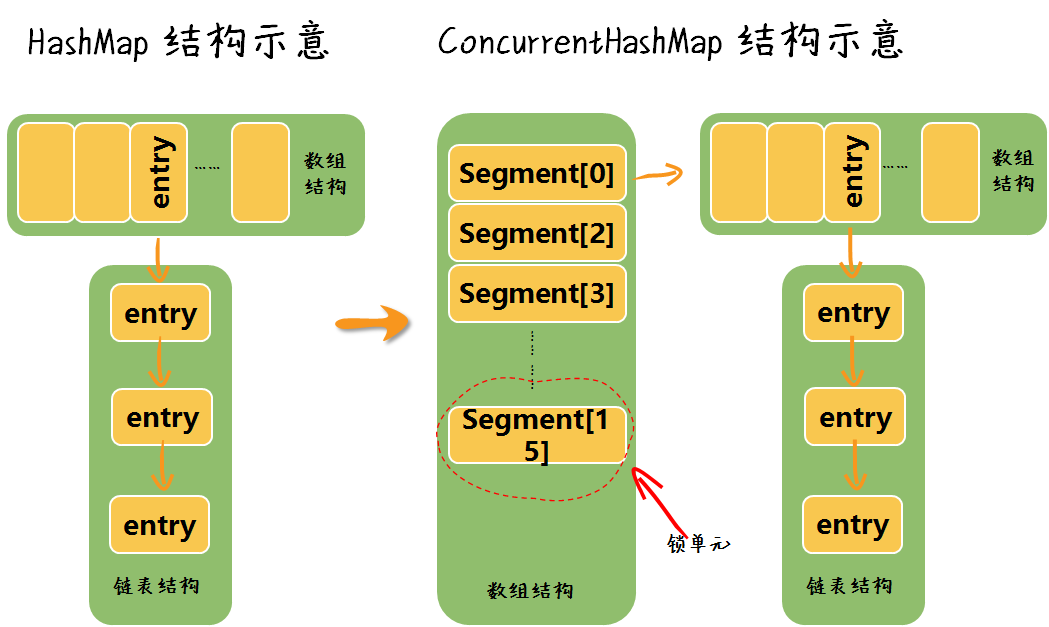
概念已经了解了,ConcurrentHashMap 工具类最基本的用法是怎样的呢?看下面。
3. 基本用法
// 创建一个 ConcurrentHashMap 对象
ConcurrentHashMap<Object, Object> concurrentHashMap = new ConcurrentHashMap<>();
// 添加键值对
concurrentHashMap.put("key", "value");
// 添加一批键值对
concurrentHashMap.putAll(new HashMap());
// 使用指定的键获取值
concurrentHashMap.get("key");
// 判定是否为空
concurrentHashMap.isEmpty();
// 获取已经添加的键值对个数
concurrentHashMap.size();
// 获取已经添加的所有键的集合
concurrentHashMap.keys();
// 获取已经添加的所有值的集合
concurrentHashMap.values();
// 清空
concurrentHashMap.clear();
是不是很简单,那 ConcurrentHashMap 应用在哪些场合比较合适呢?下面我们给出最常用的场景说明。
4. 常用场景
我们在多线程场合下需要共同操作一个 HashMap 对象的时候,可以直接使用 ConcurrentHashMap 类型而不用再自行做任何并发控制,当然也可以使用最常见的 synchronized 对 HashMap 进行封装。推荐直接使用 ConcurrentHashMap ,是仅仅因为其安全,相比全局加锁的方式而且很高效,还有很多已经提供好的简便方法,不用我们自己再另行实现。
举一个日常研发中常见的例子:统计 4 个文本文件中英文字母出现的总次数。为了加快统计处理效率,采用 4 个线程每个线程处理 1 个文件的方式。此场合下统计结果是多个键值对,键是单词,值是字母出现的总次数,采用 Map 数据结构存放统计结果最合适。考虑到多线程同时操作同一个 Map 进行统计结果更新,我们应该采用 ConcurrentHashMap 最合适。请看下面代码。
5. 场景案例
import java.util.Random;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicLong;
public class ConcurrentHashMapTest {
// 创建一个 ConcurrentHashMap 对象用于存放统计结果
private static ConcurrentHashMap<String, AtomicLong> concurrentHashMap = new ConcurrentHashMap<>();
// 创建一个 CountDownLatch 对象用于统计线程控制
private static CountDownLatch countDownLatch = new CountDownLatch(3);
// 模拟文本文件中的单词
private static String[] words = {"we", "it", "is"};
public static void main(String[] args) throws InterruptedException {
Runnable task = new Runnable() {
public void run() {
for(int i=0; i<3; i++) {
// 模拟从文本文件中读取到的单词
String word = words[new Random().nextInt(3)];
// 尝试获取全局统计结果
AtomicLong number = concurrentHashMap.get(word);
// 在未获取到的情况下,进行初次统计结果设置
if (number == null) {
// 在设置时如果发现如果不存在则初始化
AtomicLong newNumber = new AtomicLong(0);
number = concurrentHashMap.putIfAbsent(word, newNumber);
if (number == null) {
number = newNumber;
}
}
// 在获取到的情况下,统计次数直接加1
number.incrementAndGet();
System.out.println(Thread.currentThread().getName() + ":" + word + " 出现" + number + " 次");
}
countDownLatch.countDown();
}
};
new Thread(task, "线程1").start();
new Thread(task, "线程2").start();
new Thread(task, "线程3").start();
try {
countDownLatch.await();
System.out.println(concurrentHashMap.toString());
} catch (Exception e) {}
}
}
观察输出的结果如下:
线程1:is 出现1 次
线程2:is 出现2 次
线程2:it 出现1 次
线程2:it 出现2 次
线程1:is 出现3 次
线程1:is 出现4 次
线程3:is 出现5 次
线程3:we 出现1 次
线程3:is 出现6 次
{is=6, it=2, we=1}
其实 ConcurrentHashMap 在使用方式方面和 HashMap 很类似,只是其底层封装了线程安全的控制逻辑。
6. 几个其他方法介绍
-
V putIfAbsent(K key, V value)
如果 key 对应的 value 不存在,则 put 进去,返回 null。否则不 put,返回已存在的 value。 -
boolean remove(Object key, Object value)
如果 key 对应的值是 value,则移除 K-V,返回 true。否则不移除,返回 false。 -
boolean replace(K key, V oldValue, V newValue)
如果 key 对应的当前值是 oldValue,则替换为 newValue,返回 true。否则不替换,返回 false。
7. 小结
本节通过一个简单的例子,介绍了 ConcurrentHashMap 的使用场景和基本用法。希望大家在学习过程中,多思考勤练习,早日掌握之。

 2026 imooc.com All Rights Reserved |
2026 imooc.com All Rights Reserved |