



前言
在上一节我们介绍了什么是微服务并且从概念上理解了微服务定义,根据 Martin Fowler 的介绍,我们整理出来微服务的几个核心点
- a suite of small services:一组小的服务;
- running in its own process:独立的进程;
- communicating with lightweight:轻量级的通讯;
- built around business capabilities:基于业务能力构建;
- independently deployable:独立部署;
- a bare minimum of centralized management:最小的中心化管理。
知其然比知其所以然,微服务更多是一种风格,这一节起,我们开始进行概念落地,向微服务架构迈出第一步。
1. 向微服务架构迈出的第一步
如果已经决定要从单体架构切换为微服务架构,我们不应该纠结使用什么框架,到底是用 Dubbo 还是 SpringCloud?注册中心是选择 ZooKeeper 还是 Eureka ?首先我们最应该了解的点是:
- 微服务能给我们带来了什么好处,帮我们解决了什么问题;
- 也要了解到微服务给我们带来了多少的挑战,为此我们必须付出什么代价;
- 还要明确的了解到微服务因为协同方式不同,为此我们必须更新我们的人员组织架构;
在第一节中,我们提到了一个点,就是微服务只有在业务达到临界点的时候采用微服务才能达到生产力更优,当我们的业务成长到足够的复杂,团队达到一定得规模,仅仅依靠好的设计已经不能保证组件之间有清晰的边界,这个时候将组件之间的边界强制变成个独立服务间的边界会有很大的帮助。
2. 微服务与团队之间的关系
刚开始的互联网公司业务体量都不大,刚开始一般都会尝试业务模式是否能跑得通,所以一般来说一开始的系统是一个简单的系统,很可能是一个单体应用,团队的规模也是不大,十来个人就顶天了。
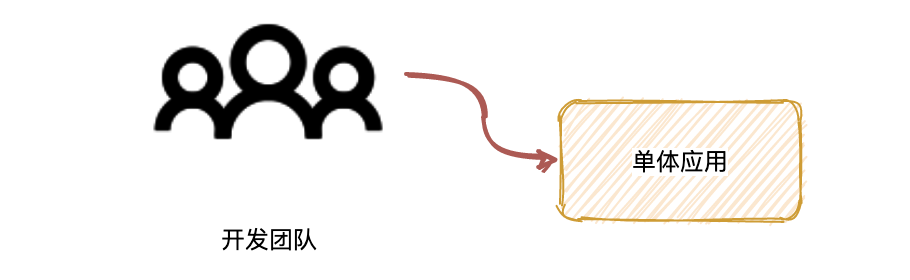
但随着业务的增长,原来只有一个小团队可能就顶不住这么大的工作量了,会分成几个小团队,甚至会有更多团队加入协同。例如我们公司,从一开始的开发小组,就变成了开发 1 组,开发 2 组,开发 3 组。但是我们的系统还是一个单体应用,那么它跟分散式团队产生了不匹配的情况,这个时候在团队之间沟通和协调成本就变得很高,交付效率降低
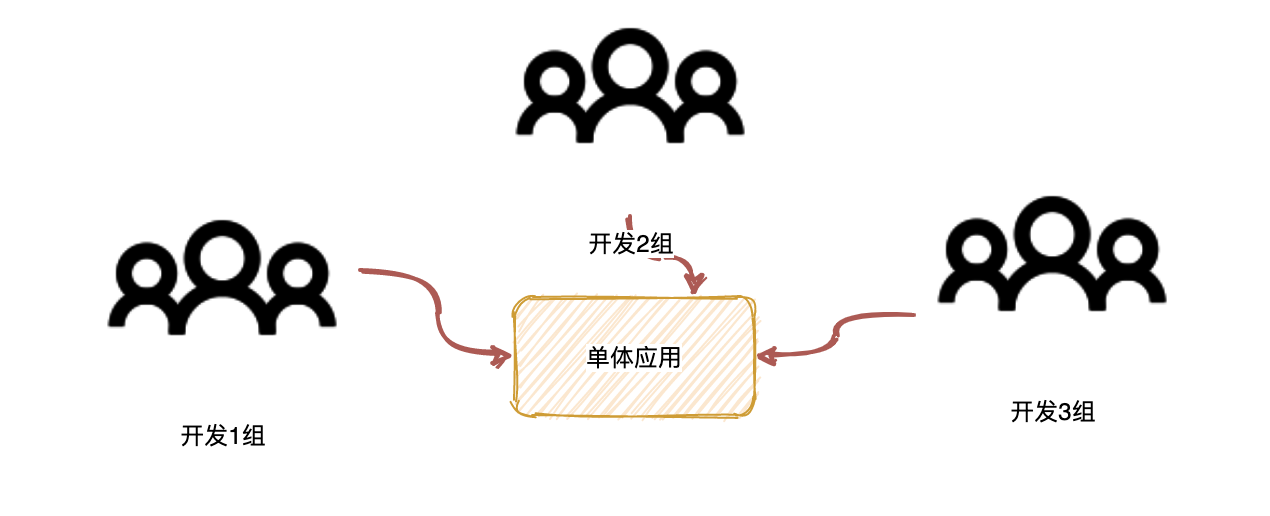
几个团队共同对一个单体应用的代码去开发和维护,如果一个团队对这个单体结构进行改造引入一些新的功能或新的技术时,往往需要其他团队的协作配合,连同做集成测试,运维部署才能交付这个应用。这时,不仅仅是代码版本难以维护,团队之间的沟通协调成本变成很高,也往往容易产生摩擦。
为了给解决这个问题提供理论支撑,在微服务盛行的今天,1967 年的康威讲过的一段话也被翻出来,就是出名的康威定律。
康威定律
康威是一个程序员,康威定律是他在 1967 年提出来的,他的原话是这样:
Organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations. - Melvin Conway(1967)
中文直译过来大概的意思就是,设计系统的组织,其产生的设计等同于组织之内、组织之间的沟通结构。
直白一点说,就是我们需要什么样的系统就要搭配什么样的团队,当我们的系统是根据业务边界进行划分的话,我们就要按照业务的边界进行团队的切分。
上面所描述的问题,其实就是多团队之间和单体应用生产不匹配,违反了康威法则。
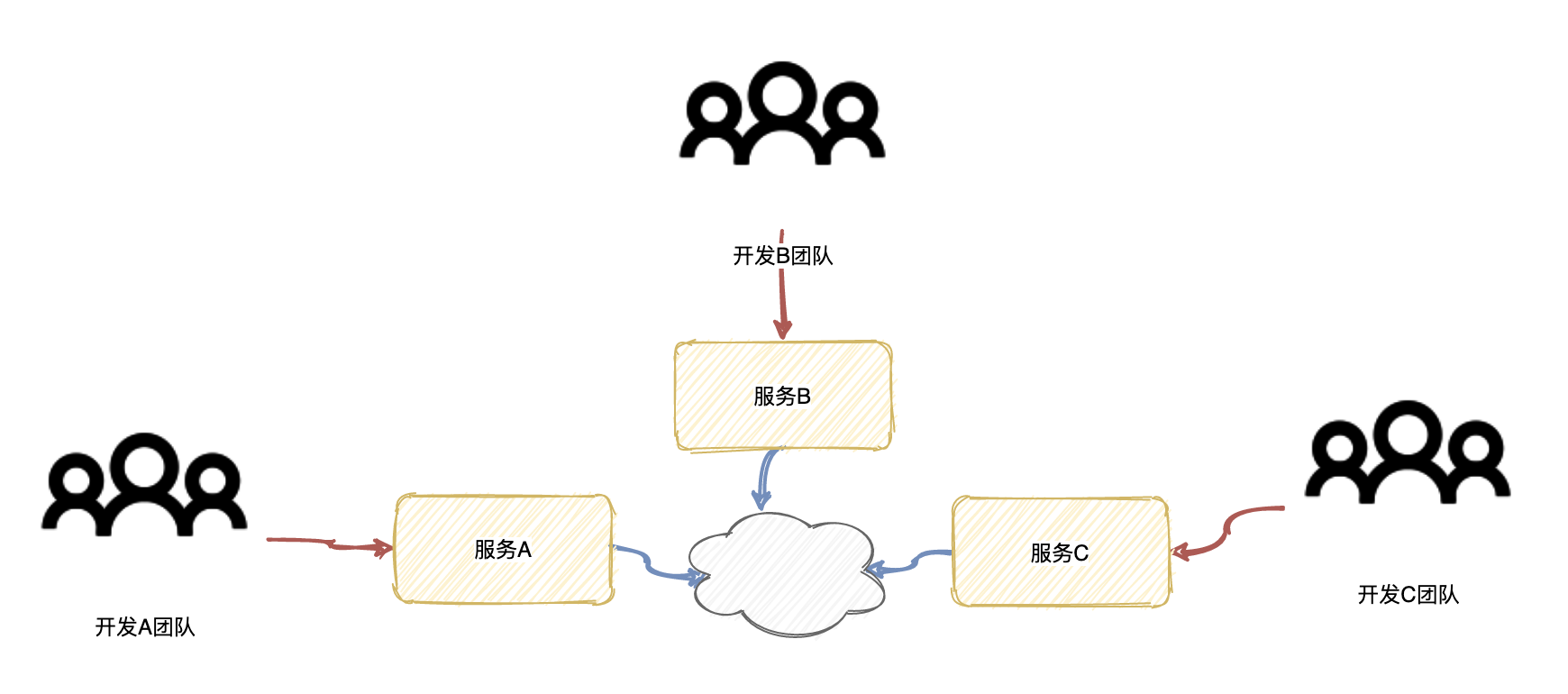
而微服务则把单体应用拆分成若干独立的应用,把一个大团队拆分为若干独立的小团队,每个团队负责自己的服务,相互之间不干扰,当团队 A 负责的服务 A 进行开发修改并不需要其他团队沟通配合,或者说沟通和配置成本变得比较少,一般只发生在双方边界交集的地方,那么这个时候发现多团队和微服务之间架构的关系可以映射起来,它符合了康威定律,整体的研发效率会更加高效。
所以说,单体架构转型微服务架构,不仅要考虑技术的转型,我们的开发团队也要进行转型!!
3. 权衡利弊
凡是都有利弊,实施微服务肯定也不是只有好处。架构设计最重要的一点就是权衡,我们不仅要知道转型微服务能带来什么好处,同时也要明确知道微服务会给我们带来什么挑战。下面我们先来看下微服务给我们带来的好处有哪些呢?
3.1 利:
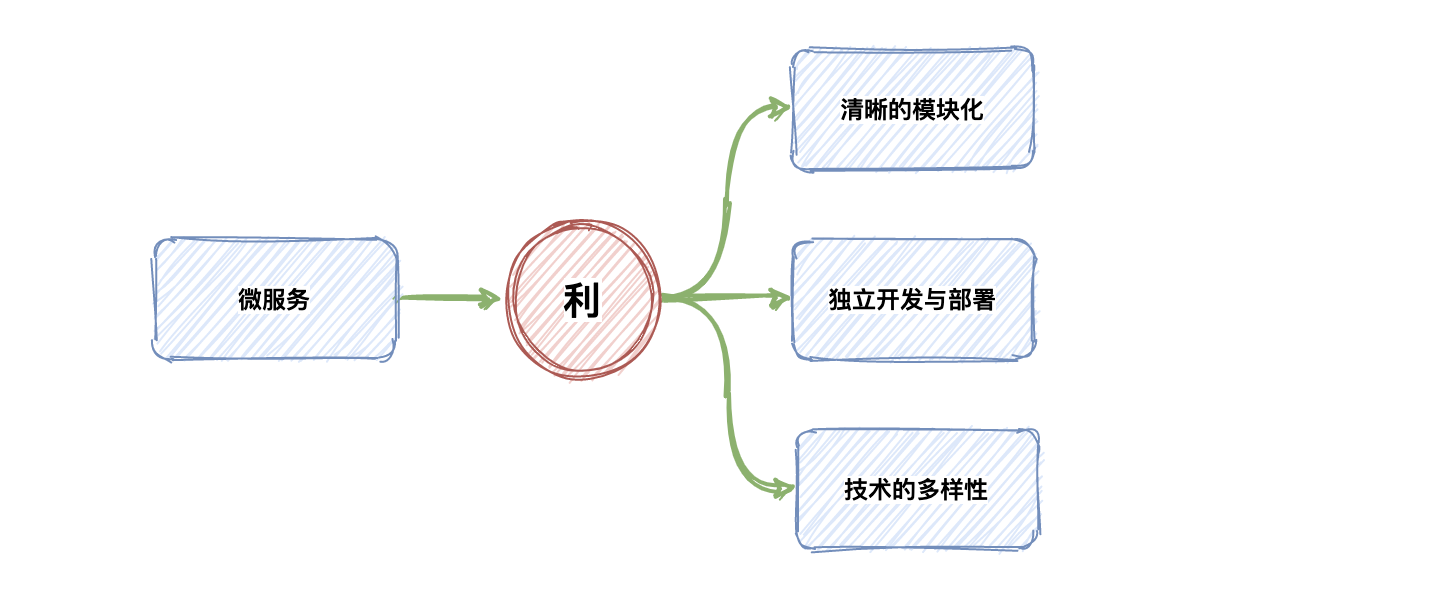
清晰的模块化
我们知道在做软件设计,经常提到 “高内聚,低耦合”,其中模块化就是非常重要的一点。
正如我们写代码一样,一开始我们写程序,我们采用类的方式来做模块,后面开始采用组件或类库的方式做模块化,这样就可以做到工程上的复用,并且分享给其他人或团队来调用。
同样的道理,微服务在组件的层次上又高了一层,以服务的方式来做模块化,每个团队独立维护自己的服务,有明显的一个边界,开发完一个服务其他团队可以直接调用这个服务,不需要像组件通过 jar 包或源码的方式进行分享,所以微服务的边界是比较清晰的。
独立开发部署
每个团队可以根据产品经理提的需求进行开发测试和部署,一般来说不太需要太过依赖于其他团队进行协作,只有在双方有边界交集才需要协同,而往往在有边界交集的时候,双方往往是以接口级的方式进行交互,只要每个服务注重好自己的服务提供,暴露好提供的服务即可。
这个对比起单体应用,发布和部署需要很多团队进行写作,而且经常只要不慎,单体架构里面的业务就会相互影响。
在容量和资源的评估上,微服务的单个服务更好进行评估,大而臃肿的单体掺杂了诸多的业务逻辑,使得对资源评估往往不好下手。
技术多样性
微服务是分散式治理,没有集中治理,每个团队可以根据团队自己的实际情况和业务的实际情况去选择适合自己的技术栈,有些团队可能擅长 Java 开发,有些团队可能更偏向前端,更适合用 nodejs 去开发服务,不过这个不是越多越好,技术栈的引入也是有成本。
3.2 挑战
(注:我们不说弊,我们说挑战 _ )
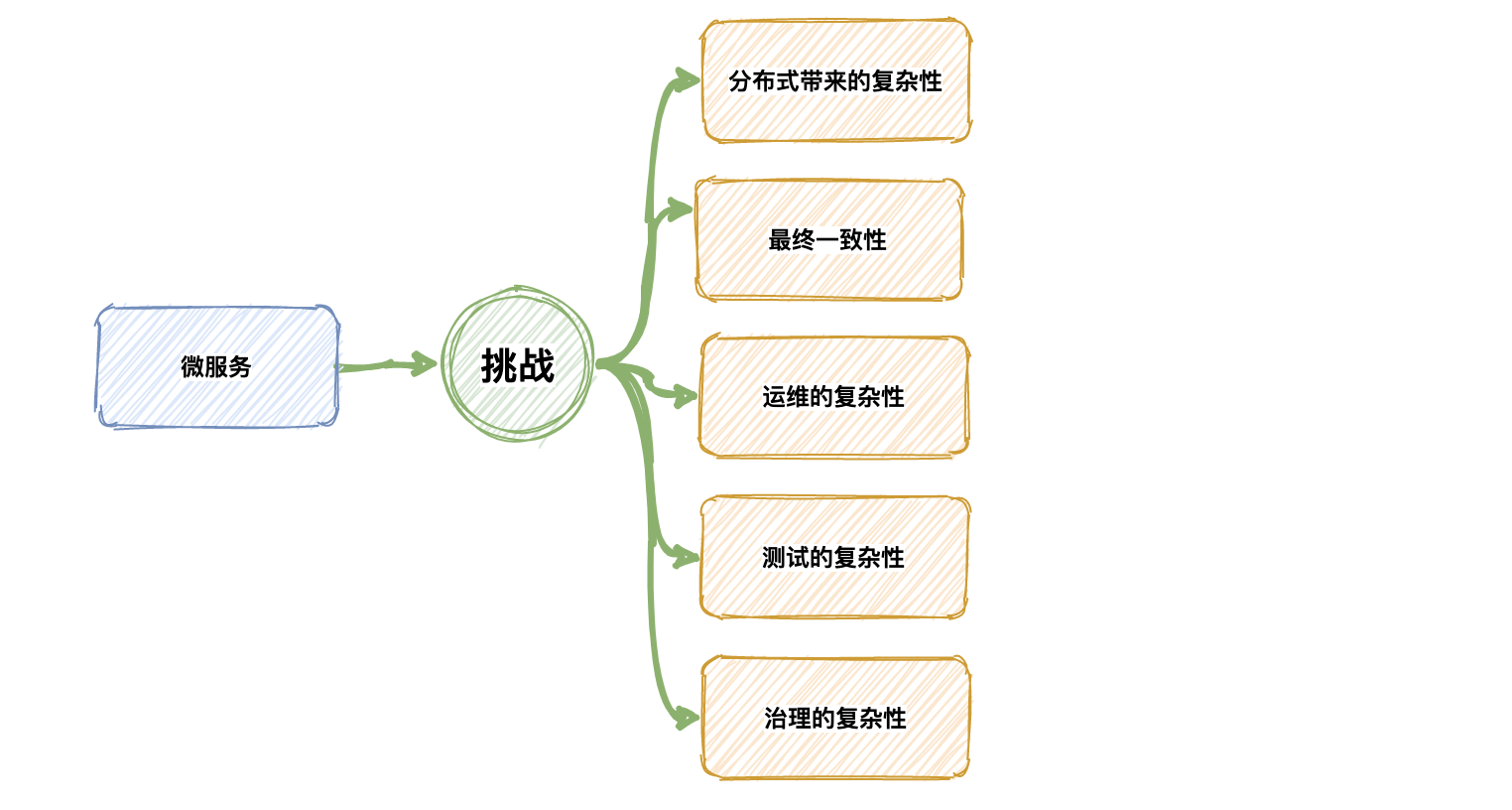
分布式带来的复杂性
在原来模块应用就是一个应用,一个对单体应用的架构比较熟悉的人可以对整个单体进行一个很好的把控。
但在微服务系统中,可能一下子一个系统就变成了好几十个服务,在一些大公司可能是上百个服务,服务与服务之间是通过接口的相互沟通形成了业务的实现,那么这个时候整个系统就变得非常复杂,一般的开发人员或一个团队都无法理解整个系统是如何工作。
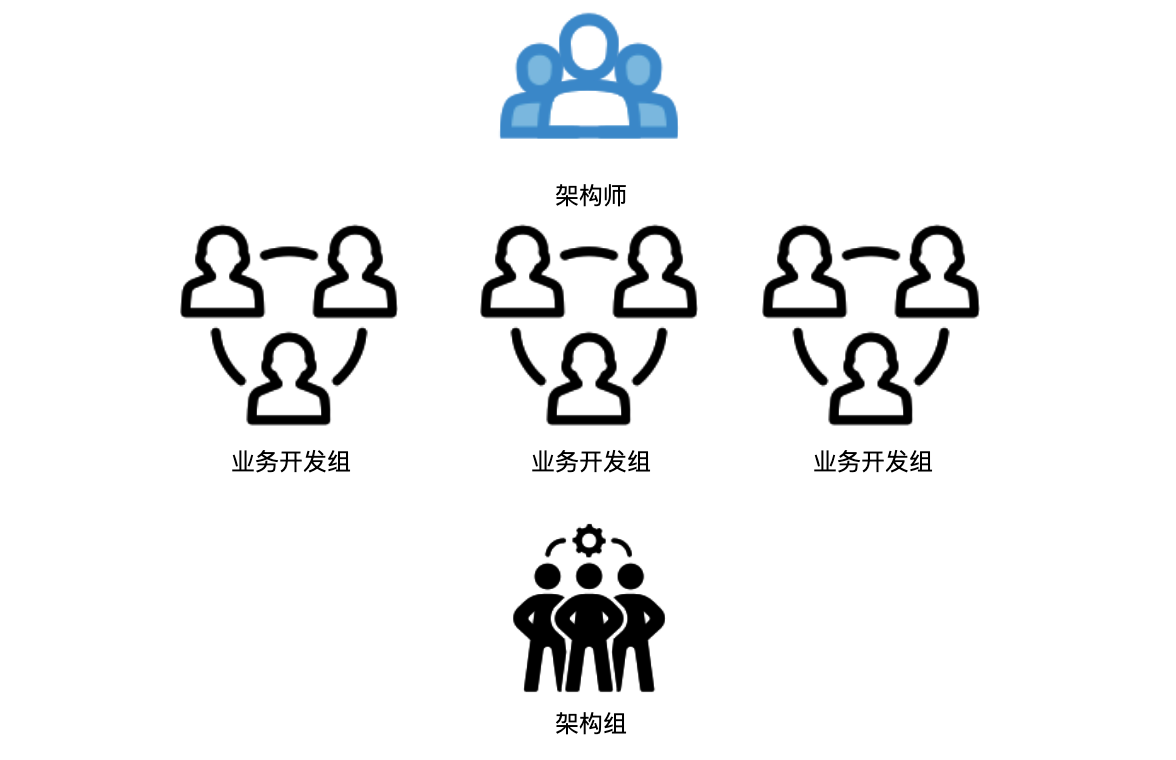
虽说分团队会带来效率提升,但在整个架构层面需要一个对业务对系统都非常了解的架构师,一旦设计不合理,交叉调用,相互依赖频繁,就会出现牵一发而动全身的局面。
项目多了,轮子的需求也会变多,各个项目中很容易就出现重复造轮子的现象,这个时候需要有人专注公共代码,公共模块的管控,所以有时候会在各个业务开发组上面又叠加一个小组,叫架构组,就是专门干这事。
数据最终一致性
由于微服务本身服务是分散的,所以背后的数据也是分散的,每个团队都有自己的数据源,比如团队 A 有订单数据,B 团队也有订单数据,团队 A 修改了订单数据是否应该同步给团队 B 的数据呢,这里就涉及到数据一致性问题。
还有就是我们会发现传统的 ACID 事务在微服务失效,在本地事务中,是由资源管理日(RM)直接提供事务支持,数据一致性在本地事务保证。但在分布式中,分布式事务比较流行的是两阶段提交(2PC),但两阶段提交也不能完全保证数据一致性问题,并且还存在同步阻塞的问题,所以提出最终一致性的说法,包含了 CAP 和 Bese 理论。
运维的复杂性
在以前的运维只需要管理的是机器 + 单体应用,而在分布式系统中存在大量的服务,服务与服务之间是相互协同和依赖,那么对分布式系统的资源,容量规划,对监控,对整个系统的可靠性和稳定性都非常具备挑战的。
测试的复杂性
对于测试人员来说,在单体应用上,一个测试团队只需要测试好一个单体应用就可以,到了分布式系统,各个服务是分布在各个团队上,这个对测试团队来说要求就很高,在做功能集成测试时是需要调动很多的团队配合去联合做集成测试。
治理的复杂性
上面说了,单体应用转型微服务决对不是考虑使用哪套微服务框架就了事了,更多的复杂性集中在治理的环节,一个公司人多了就需要一个行政部门,对公司员工进行服务(管理),一个微服务系统多了也是需要进行管理和治理。
之前说微服务拆分后,每个内部的团队可以使用丰富差异化的技术栈,但是,在协同各个服务之间环节是需要统一或者说标准化管理,例如,服务注册发现;服务的负载均衡,监控 - 日志;监控 - metrics; 监控 - 全链路跟踪;限流熔断;安全 - 访问控制;序列化;网络传输;代码管理;统一异常处理;文档;集中配置中心,后台集成 MQ,Cache;
你会发现我们整个专栏有一半的篇幅是围绕着这些治理复杂性去进行展开,这个在后续会慢慢的讲到,甚至可以这么说,整个微服务的构建,运维都是跟这些复杂性在进行搏斗,只有根据自己业务的情况克服这些复杂的因素,才能可靠的高效推进业务的进展。
4. 总结
本小节我们对微服务的利和弊进行了分析和整理,但实际情况可能远远比概念复杂,对于不同的业务不同的系统,往往成本和收益是具有不同的权重。
最终我们得回到业务和现实层面进行利弊的权衡
- 我们的技术是否有所储备 ?
- 我们是否要构建一个较大的平台 ?
- 我们的团队是否需要扩展 ?
好了,几点思考。下一节我们将开始对微服务的服务和技术架构进行分层。