



故事背景:
人物:
大牛
小白
广西某高铁站所有乘客
场景:
美食和知识 — 对话肯德基
前言:
散列表,是根据关键码值而直接进行访问的数据结构。它通过把关键码值(通过一系列的计算)映射到表中一个位置来访问记录,以加快查找的速度。
随着 G250 次列车徐徐进站。原来趋于平静的广西高铁站重新热闹起来。旅客们带着大包小包的行李奔向出站口。
“小白,你先找个地儿等我,我先去趟洗手间……”

“好,旁边有个肯德基,我就在肯德基等你。”
小白到了肯德基找了个地方坐下等大牛。
过了不久,小白就看见大牛推开肯德基的门。”牛哥,这儿!“
“去了一趟洗手间,感觉一身轻松啊。小白啊,哥哥现在很开心,所以我决定考一考你。怎么样,现在有没有兴趣挑战一下?”。大牛刚坐下就开始一脸奸笑地看着小白。
“不是吧牛哥,这一路你都考我三次了,就不能让我消停消停。”
“让你学习还委屈了是吧,你将来这样怎么升职加薪,怎么走上人生巅峰。”
“得得得,我投降,考就考呗,有什么大不了的。有什么问题放马过来吧,我接着就是了。”
“哼,刚才我找你的时候,先去了旁边那家肯德基,但是没有看到你,到这儿之后才看见你在这儿。你说说,这种情况,跟一种数据结构相似。”
“不就是散列表吗,我一想就想到了。”
“为什么是散列表呢?”
“现在就让本白给你解答一下。”
1. 哈希表定义
-
散列表也叫哈希表(以下统称哈希表),是根据关键码值而直接进行访问的数据结构;
-
把关键码值映射到表中的方法 — 哈希函数;
-
存放记录的表 — 实际存储结构 。
哈希表其实就是通过哈希函数来确定一个位置,然后再表中的这个位置来存储数据。
例如:
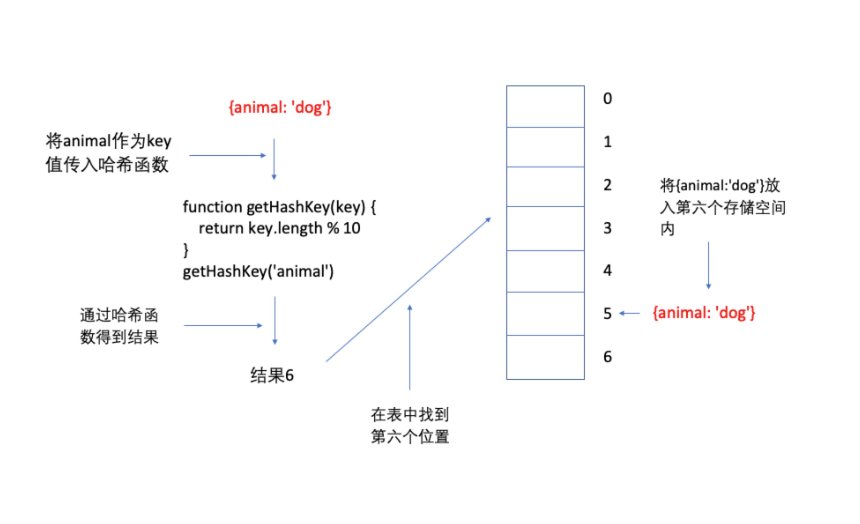
“刚才你在找我的时候,首先是先查看站内肯德基的店在哪。然后就去店里找我。这种情况也只有哈希表合适嘛。”
“嗯,讲得还可以。现在换一种方式,用代码实现一遍吧。” 说着大牛从包里拿出纸笔递给小白。
“牛哥,这都什么时候了,还考手写代码呢。这套早就过时了。不过,既然您这出招了,我咋的也得接着不是。”
哈希表最重要的是哈希函数,存储的过程也是计算哈希函数的过程。
哈希表实现思路:
- 创建存储位置 — 建立一个数组用来存放元素;
- 创建哈希函数 — 这是哈希表最重要的一步;
- 通过计算后的位置存储元素。
class HashMap {
constructor() {
// 创建一个数组用来存放元素
this.list = [];
}
// 创建哈希函数 并通过传入key值 得到code值
hashCode(key) {
return key.length % 10
}
// 创建存储元素的方法
put(key,value) {
this.list[this.hashCode(key)] = value;
}
// 创建获取元素的方法
get(key){
return this.list[this.hashCode(key)];
}
// 删除表中的元素
remove (key) {
this.list[this.hashCode(key)] === undefined;
}
// 清空表
clear() {
this.list = [];
}
}
// 初始化散列表
const hashMap = new HashMap();
// 存入一个元素
hashMap.put('animal', 'dog');
// 获取元素
hashMap.get('animal'); // 输出dog
这样,一个基本的哈希表结构就实现了。
“嗯嗯,写的不错嘛。这样确实是能实现一个简单的哈希表结构,但是不会有什么问题吗?”
“别着急啊牛哥,我就知道您会刨根问底。请听我接着往下说。”
上面我们也说过了,哈希函数是哈希表最重要的组成部分。对于哈希函数的定义我也知道几种方法。
2. 哈希函数
2.1 直接给定地址法
例如:人口统计表,统计 1-100 岁的人数。这种表可以直接使用年龄作为地址,无需经过哈希计算。
function hashCode(age) {
return age;
}
2.2 数字分析方法
如:
/* 一个班级的学生要统计出生日期
年。月。日
96.10.07
96.12.16
96.05.17
96.05.11
96.12.08
96.11.13
……
*/
这种情况下的数据经过分析,只有前三位的重复性是比较大的,取前三位造成的冲突可能会比较大,所以我们尽量不用前三位,只用后三位会比较好。
2.3 平方取中法
如:
function hashCode(key) {
const len = `${key.length * key.length}`;
return len.slice(1,len.length - 1)
}
hashCode('my name is xiaobai');//得到的结果为 324取最中间的一位 === 2
2.4 取余法
这个方法我们在例子中使用了。即以哈希表存储长度作为除数取余。
// 如果 哈希表最大存储长度为 30
function hashCode(key) {
return key % 30
}
2.5 随机数法
function HashCode(key) {
return Math.floor(Math.random() * key.length);
}
// 得到一个随机的位置
“一口气说这么多,我嘴都干了。”
“不错不错,小白讲解得很透彻。来来来,喝口水,继续往下说。”
3. 哈希冲突
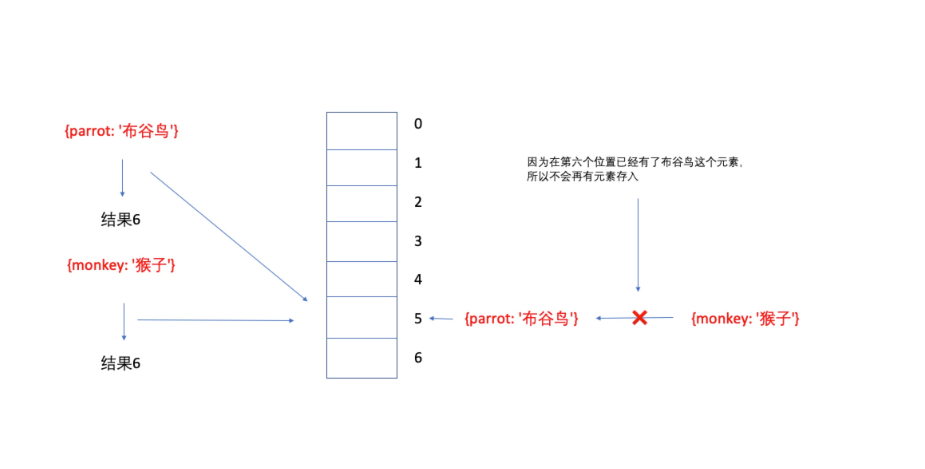
剩下的一部分是哈希冲突。冲突就是两个 key 经过哈希函数处理后得到了一样的值。

无论我们设计得有多么精细,都逃脱不了冲突的命运。所以,我们需要一些手段来避免或者是解决这种冲突现象。
3.1 链地址法
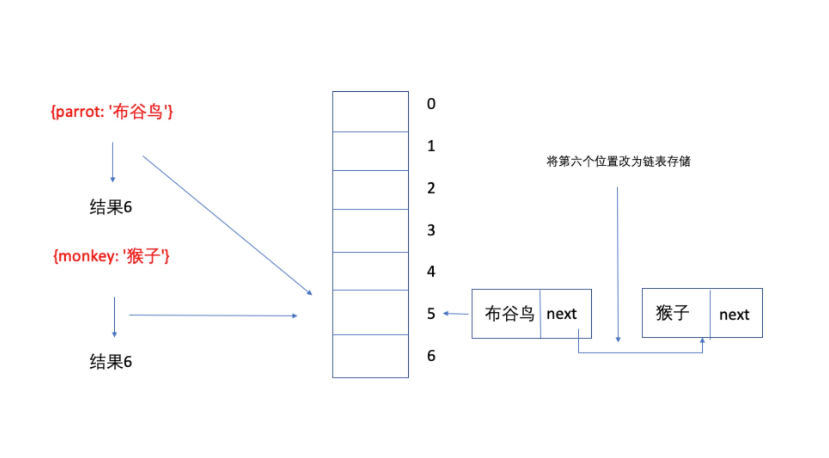
如果我们在添加元素的过程中发现要添加的位置已经有了一个元素存在,那么我们可以将这个地址的结构改变为链表存储。
如:
可修改为:
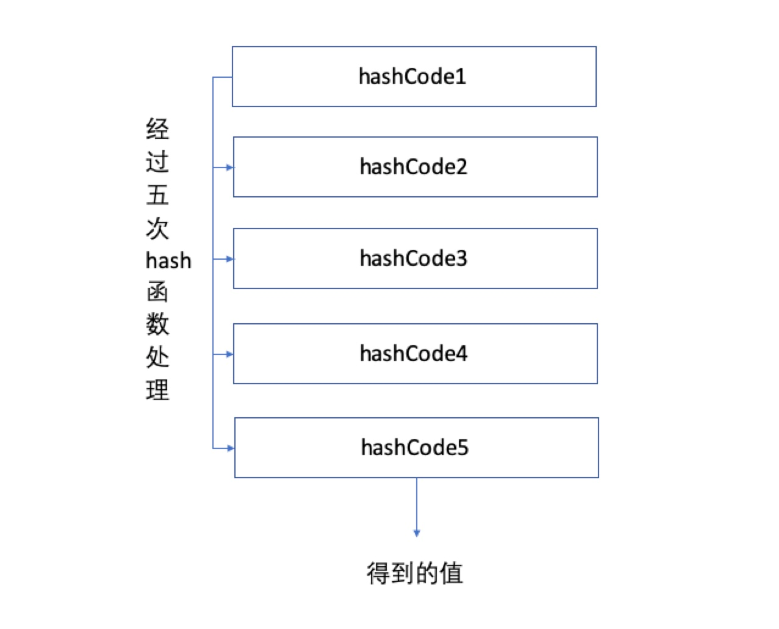
3.2 多哈希法
多设计几种哈希函数:
function hashCode1() {};
function hashCode2() {};
function hashCode3() {};
function hashCode4() {};
……
一种哈希函数导致冲突的可能性比较大,但是设计两种甚至多种哈希函数虽说还是有冲突几率,但是可以将这种几率降到最低。
3.3 开放地址法
开放地址有一个公式: KaTeX parse error: Expected 'EOF', got ')' at position 40: …,2,...,k(k<=m-1)̲
m 为表的长度,d 为每次的增量。
这种方式称为线性探测再散列 — 每次发现冲突后向后移动一个位置。
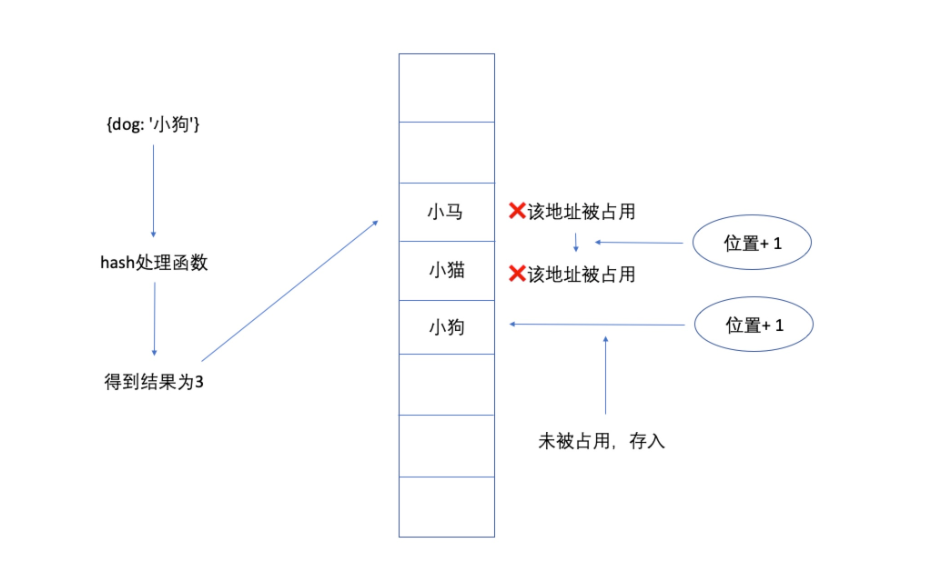
3.4 桶地址法
“为表中的每个地址关联一个桶,如果桶已经满了,就使用开放地址法处理。”
“来,再说一个基本的问题,哈希表的时间和空间复杂度各是多少?”
时间复杂度:
空间复杂度:
哈希表的执行效率是使用空间来换取时间的。获取元素只需要知道 key对应的 hash 值,所以时间复杂度为 。
如果需要添加 n 个元素到哈希表中,至少需要映射 n 次,所以一个哈希表的期望空间复杂度为
“不错不错,今天的回答让我很满意。现在赶快到酒店去吧,好好休息休息。这几天的工作可能会很累。”
“革命工作一块砖,哪里需要哪里搬。工作嘛,哪有不累的。”
“说的也是,那我们现在出发吧。”
“……”
小结:
本节主要讲述了
1.什么是散列表;
2.哈希函数的定义方式 – 直接给定地址、数字分析、平方取中、取余、随机数;
3.哈希冲突的产生和解决方法-- 链地址法、多哈希法、开放地址法、桶地址法。
努力学习的你,加油!!!

番外篇
面试题攻坚战 — 肆:
替换 val 值。并且保证替换前相同的节点替换后也相同
注:使用时间复杂度尽可能小的算法(解题方式不唯一)
// 替换前 第4 8 24 行的val相同,替换后,这几行的val依然相同。
let data = [
{
val: 1.235464654,
child: {
val: 0.656464848,
child: {
val: 1.235464654,
child: {
val: 1.467487978,
child: {
val: 0.656464848,
child: {
// ………………
}
}
}
}
}
}
];
解:
const map = new Map();
replaceSameElement(data);
// 遍历data
function replaceSameElement(data) {
data.forEach(item => {
deepReplace(item)
})
}
// 遍历data中每个元素的后继节点
function deepReplace(child){
// 首先获取map中存储的值
let middle = map.get(child.val);
if (!middle) {
// 如果没有获取到,就重新生成一个,并且存储到map中
middle = (Math.random() * 10).toFixed(9);
map.set(child.val, middle);
}
// 将节点的val值替换成获取到的值
child.val = middle;
// 如果还有后继节点,则递归替换
if (child.child) {
deepReplace(child.child)
}
}
解题思路
- 首先需要创建一个表,用来存储生成的随机数;
- 循环遍历 data 下第一层的子节点,由于 data 为数组,所以使用 forEach 来遍历;
- 创建一个新的函数用来遍历第二层之后的子节点;
- 查询节点的 val 值,如果 map 中有保存,则说明之前有生成过,此时直接拿到存储的值替换到 child.val 中即可;
- 如果在 map 中没有获取到值,则重新生成一个,并且保存到 map 中;
- 若还有后继的 child 节点,则递归替换。