

-
机器学习就是从历史数据中寻找规律查看全部
-
机器学习算法分类
算法分类1:有监督学习、无监督学习、半监督学(强化学习,举例:小孩学走路,一开始走不稳,随着数据量的增大,走的越来越熟练。);
算法分类2: 分类与回归、聚类、标注;
算法分类2:生成模型、判别模型。
查看全部 -
机器学习由数据质量决定结果,算法往往差距不大。
查看全部 -
机器学习的定义:利用计算机从历史数据中找出规律,并把这些规律用到对未来不确定场景的决策。
查看全部 -
2024.12.02 02:37
听完第一遍!机器学习课。查看全部 -
 RT.查看全部
RT.查看全部 -
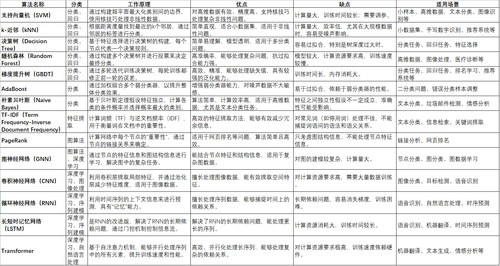
1. 决策树算法(C4.5, CART)
无监督学习:实际上,决策树通常用于有监督学习,因为它依赖于标注数据进行训练。可以根据特征来划分数据,进行分类或回归。
C4.5和CART:虽然这两者在过去很常见,但如今更先进的算法(如XGBoost)已取代它们。可以考虑添加对这些新算法的简要介绍。
2. K-Means(无监督学习)
聚类算法非常适合于无监督学习。K-Means通过最小化每个点到质心的距离来分组,适用于大多数情况下数据分布较为均匀的情况。
3. SVM(支持向量机)
支持向量机是一个非常强大的分类与回归算法,尤其适用于高维数据。尽管深度学习在某些任务中已超越它,SVM仍然是经典的高效分类算法之一。
4. Apriori
已淘汰的算法,确实因其计算复杂度和多次扫描数据库的需求而受到批评。FP-Growth是更高效的替代者,它通过树形结构减少了对数据库的访问次数。
5. EM算法
作为一种统计学习方法,EM算法的理解确实有一定的门槛,适用于混合模型或缺失数据处理等问题。
6. PageRank
虽然PageRank仍然广泛应用于搜索引擎中,但其具体实现细节已经有许多创新和优化,尤其是在大规模图数据的处理上。
7. AdaBoost
这是一种集成学习方法,可以与弱分类器(如决策树)结合,通过加权的方式提高整体分类准确率。它在图像识别中有广泛应用。
8. kNN(k-近邻)
与K-Means的不同之处在于,kNN是基于距离的分类方法。它简单易懂,但对于大数据集来说计算复杂度较高。
9. Naive Bayes
适用于分类任务,特别是在文本分类中,如垃圾邮件检测。其假设特征之间相互独立,这在实际数据中可能不完全成立,但通常仍能获得不错的效果。
高级算法:
FP-Growth
在Apriori的基础上优化了计算效率,尤其适用于关联规则挖掘。
逻辑回归
非常重要且广泛使用,尤其是在二分类问题和概率预测中。
随机森林(RF)和GBDT
两者都是决策树的集成算法,广泛用于分类与回归问题。GBDT在处理非线性问题时表现尤为出色。
推荐算法
推荐系统广泛应用于电商、社交平台中,有很多优化方法,如协同过滤、内容推荐等。
LDA(潜在狄利克雷分配)
主要用于主题模型,在文本挖掘中有重要应用。
Word2Vec
用于将词语转化为向量表示,是文本数据处理中的一个重要技术。
HMM与CRF
隐马尔可夫模型与条件随机场都广泛应用于序列数据建模,如语音识别、自然语言处理。
深度学习
包括CNN、RNN等深度神经网络,是目前处理大规模复杂数据(如图像、语音、文本)最前沿的技术。
查看全部 -
机器学习算法分类(1): 通过模型判断Y和X的关系
有监督学习:分类算法——Y类:垃圾邮件
X类:正常邮件
回归算法
无监督学习: 聚类 (无Y类)
半监督学习:强化学习
机器学习算法分类(2):
分类与回归
聚类
标注,给每一个对象打上标签,如句子的主谓宾切割
机器学习算法分类(3)【重要】
生成模型:(陪审团)属于某类的可能性。
判别模型: (法官)直接给函数,定结果。
查看全部 -
什么是机器学习
生活中的机器学习
数据分析和机器学习
常用算法
框架
demo
查看全部 -
重新开始学习一遍吧。
 查看全部
查看全部 -
机器学习与数据分析?
 查看全部
查看全部 -
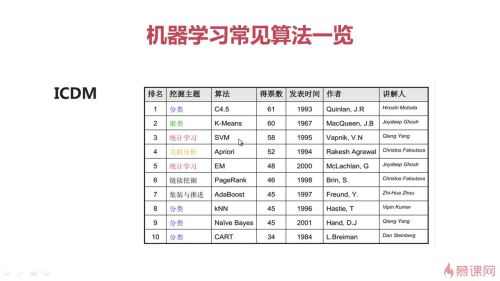
机器学习常见算法(1)ICDM
1.分类---C4.5使用决策树算法,可以解决【分类】&【回归】问题;
2.聚类---K-Means算法,属于无监督方法,解决电信用户分类问题;
3.统计学习---SVM(支持向量机)可以解决分类(主)和回归问题,有很好的表现和深厚的数学理论支撑,曾经被认为是最好的分类算法。现在光芒被【深度学习】掩盖了。有一定的数学门槛,面试中经常被问。
4.关联分析---Apriori应用于“尿片和纸尿裤”案例,最早解决了频繁项集问题。由于需要频繁访问数据库,已被淘汰。取代它的是华人开的【FP-Growth】算法。应用:电商的推荐系统,但目前有更好的替代方法。
5.统计分析---EM算法是一个算法框架,用于解决一系列问题。
6.连接挖掘---PageRank。Google使用的网页排序算法,很著名。
7.集装与推进---AdaBoosts算法,应用于人脸识别,本质为改进的决策树算法,属于有监督的分类算法。
8.分类---kNN。相对简单的分类算法,有监督。
9.分类---Naive Bayes朴素贝叶斯算法,用于识别垃圾邮件。
目前不常用的算法:Apriori和CART。 查看全部
查看全部 -
机器学习解决问题的框架
1)预测问题:
1.1分类:离散型变量
1.2回归:连续性变量
2)聚类问题:
3)确定目标:
业务需求-数据-特征工程(数据预处理,70%,最重要)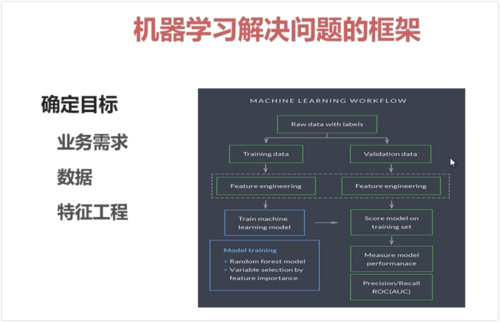 查看全部
查看全部 -
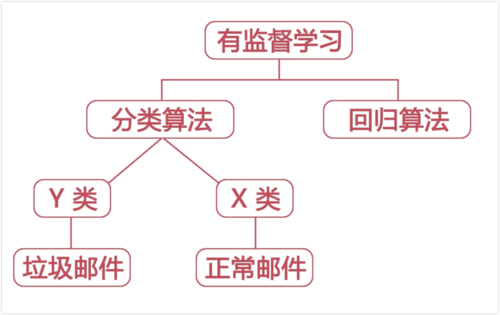
算法分类1:根据数据有无标签Y进行分类
对样本数据进行一些训练,得到模型,通过模型判断X与Y的关系。
有监督学习:训练数据中已经明确给出了该数据的Y,给数据打上了标签。如:已对邮件打上了“垃圾邮件”、“正常邮件”的标签。包括:分类算法、回归算法。
无监督学习:训练数据并没有Y,数据没有任何标签。典型算法:聚类。
半监督学习:也叫强化学习,数据越多,模型越好。
算法分类2:根据解决问题进行分类
分类与回归、聚类、标注
算法分类3(重要,直指本质)
生成模型:用来说明分类问题。返回的是属于各个类的概率。
判别模型:用来说明分类问题。直接给一个函数,数据输入到函数中,直接返回类别。


 查看全部
查看全部 -
2、解决业务问题不同
数据分析,报告历史上发生的事情。
机器学习:通过历史上发生的事情,来预测未来的事情。
3、技术手段不同
数据分析:分析方式是用户(数据分析师)驱动的,交互式分析。分析能力受限于数据分析师的能力,数据属性和维度很有限。
机器学习:分析方式是数据驱动的,自动进行知识发现。分析能力不受限于人,数据属性和维度数量级很大。
4、参与者不同
数据分析,分析师能力决定结果,目标用户是公司管理决策层。
机器学习,数据质量决定结果,目标用户是个体。
 查看全部
查看全部 -
机器学习与数据分析的区别
处理的数据类型和特点
交易数据 vS 行为数据
少量数据 vs 海量数据
采样分析 vs 全量分析
数据分析:
数据类型:主要处理交易数据,例如电商网站用户下单、银行存取款账单等。
数据量:通常涉及的数据量较少。
数据分析方法:倾向于采用采样分析,因为数据量不大,可以对样本进行深入分析。
数据一致性:对数据一致性要求严格,尤其是在金融交易等场景中,数据的准确性至关重要。
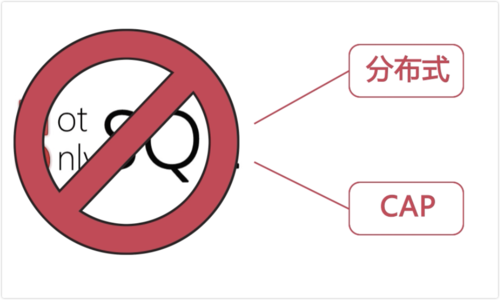
数据库使用:因此,数据分析通常使用关系型数据库,如SQL Server、MySQL、Oracle等,这些数据库能够保证事务的ACID属性(原子性、一致性、隔离性、持久性),确保数据的准确性和一致性。
机器学习:
数据类型:主要处理行为数据,例如用户的搜索历史、浏览历史、点击历史、评论等。
数据量:涉及的数据量庞大,通常需要处理海量数据。
数据分析方法:倾向于进行全量分析,以捕捉数据中的所有模式和趋势。
数据一致性:对数据一致性的要求相对较低,更注重数据吞吐量和处理速度。
数据库使用:因此,机器学习通常使用NoSQL数据库(如MongoDB)和分布式数据分析平台(如Hadoop、Spark),这些技术能够处理大规模数据集,并且具有高吞吐量和灵活性。
2. 数据处理方法和工具
数据分析:
侧重于使用统计方法和查询语言(如SQL)来分析数据,以支持决策制定。
工具和语言包括Excel、R、Python(Pandas库)等。
机器学习:
侧重于使用算法和模型来从数据中学习模式,并进行预测或分类。
工具和框架包括TensorFlow、PyTorch、Scikit-learn等。



-----

用 Nosql 处理行为数据,跟钱相关的数据,是不会用 nosql 去处理的。
 查看全部
查看全部 -
什么是机器学习?
利用计算机从历史数据中找出规律;并把这些规律用到对未来不定场景的决策
机器学习的典型应用
关联规则:啤酒+纸尿片,购物篮分析
聚类:用户细分精准营销
朴素贝叶斯:垃圾邮件检测
决策树:风险识别
ctr预估:互联网广告:百度的前多少个词条(商业广告)(按照点击率排序)
协同过滤:推荐系统(电商购物车推荐,应用市场下载应用后的推荐等等)
自然语言处理:情感分析(对文本抓关键情感词),实体识别(提取文本主要数据,人名等)
深度学习:图像识别
更多应用:语音识别,人脸识别,手势控制,智慧机器人,实时翻译
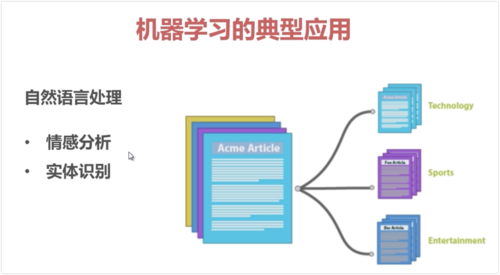


 查看全部
查看全部 -
机器学习的典型应用:
购物篮分析——美国超市啤酒和纸尿裤——关联规则
用户细分精准营销—— 中国移动全球通、动感地带、神州行——聚类
垃圾邮件识别——朴素贝叶斯
信用卡欺诈——决策树

Î
 查看全部
查看全部 -
机器学习的典型应用
用户细分精准营销
• 聚类 用机器对用户群体分类,判断用户具体需要什么。
 查看全部
查看全部 -
购物篮分析
关联算法,纸尿裤和啤酒 查看全部
查看全部 -
业务系统发展的历史
基于专家经验
基于统计——分纬度统计
机器学习——在线学习

机器学习两种使用场景 离线学习和在线学习。
离线学习:批处理的方式,对以前的数据进行学习,从而运用到后面的指导中
在线学习:对实时产生的数据进行学习,再对实时得业务进行指导
两种场景使用的算法都是一样的。
查看全部 -
机器学习发展的原动力
从历史数据中找出规律,把这些规律用到对未来自动作出决定。
用数据代替expert
经济驱动,数据变现

查看全部 -
《概率论》《数据统计》是机器学习的基石
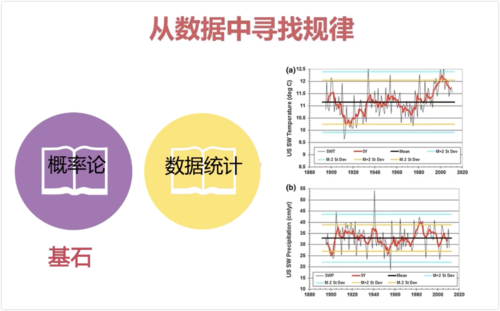
传统的统计学,受运算能力的限制,所以是用抽样的方式, 抽取一定量的样本然后进行概率统计,然后得到结论之后进行假设检验
统计学受限于计算能力,依赖于采样的方法,再反作用于原来的数据。步骤:抽样-->描述统计-->结论-->假设检验。
现在无需考虑数据量的问题,无需抽样技术,直接全样。可利用可视化技术来观察数据。要进行数据分析,需要先进行量化,用模型拟合规律,函数-->函数曲线-->拟合。高维度时很难用可视化的方法,只能用数学运算。
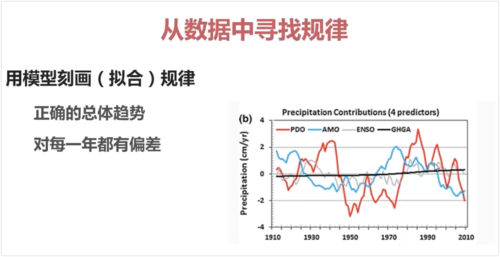 查看全部
查看全部 -
什么是机器学习?
利用计算机从历史数据中找出规律,并把这些规律用到对未来不确定场景的决策
- 判断、决策
主体的不同:计算机--机器学习、人--数据分析。数据分析是依靠人从历史数据中找到规,学习效果很大程度以来于人的经验与知识水平,
机器学习就是想要抛弃对人的依赖,靠机器来挖掘规律。
数据:机器学习只是解决问题的框架、算法,需要数据,数据量越大越准确。
规律:通过机器学习不同的算法去找规律,不同的算法结果不同。
查看全部 -
一、 demo - 图片按照色彩聚类
查看全部 -
一、机器学习解决问题的框架
训练模型
定义模型
定义损失函数
优化算法
模型评估
交叉验证
多个算法分别带入同一类数据,验证效果
效果评估
评估多个算法间的差异
查看全部 -
一、机器学习解决问题的框架
聚类问题
预测问题
二、各个算法共同的思想
机器学习 —— 确定目标
业务需求
数据
特征工程(数据预处理)
查看全部 -
一、机器学习算法
SVM:支持向量机
关联分析: FP-Growth
AdaBoot: 有监督学习,人脸识别
二、常用算法
FP-Growth
逻辑回归
搜索结果的排序等
RF、GBDT
决策树的改进
推荐算法
各个推荐系统的算法
LDA
自然语言处理算法
Word2Vetor
文本挖掘
HMM、CRF
文本挖掘
深度学习
图像识别等
查看全部 -
一、机器学习算法分类
有监督学习
分类算法
回归算法
无监督学习
聚类
半监督学习(强化学习)
其他
标注
生成模型(属于各个类的概率)
判别模型 (分类)
查看全部







举报