

-

说明
联机分析处理,简称OLAP(Online analytical processing),是计算机技术中快速解决多维分析问题的一种方法。
Online analytical processing (OLAP) is software technology you can use to analyze business data from different points of view.
查看全部 -
NO SQL 一致性弱。适合存行为数据,不适合存交易数据。
CAP:consistency, availability, and partition
查看全部 -

初级学习:专家学习
查看全部 -

用数据代替专家!
查看全部 -
从数据中寻找规律,人们干了几十年、上百年了。基础的学科:概率论和数理统计。
统计学问题:因为计算能力有限,往往采样只采少量数据
查看全部 -
从历史数据学习的 主题,是 机器 还是 人?
查看全部 -

1
查看全部 -

1
查看全部 -

机器学习常见算法
 查看全部
查看全部 -
机器学习经验分析
 查看全部
查看全部 -
机器学习规律分析是机器学习经验查看全部
-
机器学习简单认知
一.什么是机器学习:
1.利用计算机从历史数据中找到规律,并把这些规律用到对未来不确定场景的决策。
2.不确定事件:例如本年度第三季度业绩情况(判断+决策),(靠规律),而不是例如太阳从东边升起的确定性事件
3.机器学习和数据分析不同:
主体的不同:计算机--机器学习、人--数据分析。
数据分析是依靠人从历史数据中找到规,学习效果很大程度以来于人的经验与知识水平,机器学习就是想要抛弃对人的依赖,靠机器来挖掘规律。
4.
数据:机器学习只是解决问题的框架、算法,需要数据,数据量越大越准确。规律:通过机器学习不同的算法去找规律,不同的算法结果不同。规律=数学函数=数学公式
二.从数据中寻找规律
《概率论》《数据统计》是机器学习的基石
传统的统计学,抽取一定量的样本然后 进行概率统计,然后得到结论 之后进行假设检验
传统的统计学受运算能力的限制,所以是用抽样的方式;
而现在计算能力足够强,就不需要采用抽样的方式了。
做数据分析要对数据进行量化,才方便计算、比较。
传统统计:抽样-描述统计-结论-假设检验-推断
机器学习不受计算量的限制,直接跳过抽样
统计学受限于计算能力,依赖于采样的方法,再反作用于原来的数据。步骤:抽样-->描述统计-->结论-->假设检验。
现在无需考虑数据量的问题,无需抽样技术,直接全样。可利用可视化技术来观察数据。要进行数据分析,需要先进行量化,用模型拟合规律,函数-->函数曲线-->拟合。高维度时很难用可视化的方法,只能用数学运算。三.机器学习发展的原动力
1. 从历史数据中找出规律,把这些规律用到对未来自动作出决定。
2. 用数据代替expert——业务逻辑
3. 经济驱动,数据
四.业务系统发展历史
1、基于专家经验 (运维和产品头脑风暴,程序员写逻辑)
2、基于统计---分维度统计。数据分析,受限于数据分析人员的经验(数据报表,:联机事务处理OLAPP(on-line transaction processing))
3、机器学习模式
模式①:离线机器学习,每天定时更新,跑算法,生成一个新的模型,循环,生成新的模型。对昨天数据的研究,用算法分析形成一个模型,指导明天的活动。缺点:存在偶然性,没法给出正确的模型,如双11的集中购物。
模式②:在线机器学习,实时的数据进行分析,不断的形成模型对用户进行指导
五.机器学习的经典应用
(一)购物篮分析
关联算法,纸尿裤和啤酒
(二)用户细分精准营销
聚类:把用户消费数据拿过来喂给算法,计算机运算,人为设置想要分为几类。 分完类后,业务人员总结每类人员共同的消费特征。
(三)
朴素贝叶斯的算法:垃圾邮件识别
决策树: 信用卡欺诈:
ctr预估:点击预估,核心为线性逻辑回归 如:互联网广告 百度搜索的广告推广
推荐系统:协同过滤算法,例如淘宝 买此产品的人同时购买了。
自然语言处理:情感分析(对文本抓关键情感词),实体识别(提取文本主要数据,人名等)
深度学习:图像识别
更多应用:语音识别,人脸识别,手势控制,智慧机器人,实时翻译
六.机器学习和数据分析区别
1:处理的数据不同
数据分析:交易数据、少量数据、采样分析。对数据一致性要求严格,使用关系型数据库sql serve、mysql、oracle。
机器学习:行为数据、海量数据、全量分析。需要保证数据吞吐量,数据一致性可以打折扣,所以用NoSQL数据库(MongoDB、nosql)和分布式数据分析平台(Hadoop、Spark)
交易数据 :电商网站用户下单、银行存取款账单
行为数据:用户的搜索历史、浏览历史、点击历史、评论
2.解决业务问题不同
数据分析,报告历史上发生的事情。
机器学习:通过历史上发生的事情,来预测未来的事情。
3.技术手段不同
数据分析:分析方式是用户(数据分析师)驱动的,交互式分析。分析能力受限于数据分析师的能力,数据属性和维度很有限。
机器学习:分析方式是数据驱动的,自动进行知识发现。数据属性和维度数量级很大。
4.参与者不同
数据分析,分析师能力决定结果,目标用户是公司高层。
机器学习,数据质量决定结果,目标用户是个体。
七.机器学习算法分类
算法分类1:根据数据有无标签Y进行分类
对样本数据进行一些训练,得到模型,通过模型判断X与Y的关系。
有监督学习:训练数据中已经明确给出了该数据的Y,给数据打上了标签。如:已对邮件打上了“垃圾邮件”、“正常邮件”的标签。包括:分类算法、回归算法。
无监督学习:训练数据并没有Y,数据没有任何标签。典型算法:聚类。
半监督学习:也叫强化学习,数据越多,模型越好。
算法分类2:根据解决问题进行分类
分类与回归、聚类、标注
算法分类3(重要,直指本质)
生成模型:用来说明分类问题。返回的是属于各个类的概率。
判别模型:用来说明分类问题。直接给一个函数,数据输入到函数中,直接返回类别。
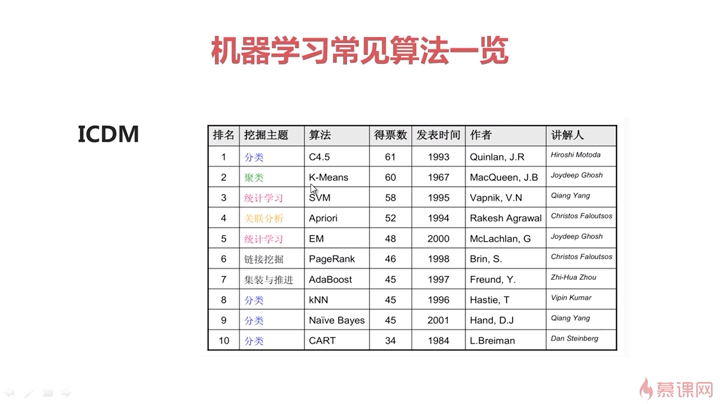
八.机器学习常见算法
1.分类---C4.5使用决策树算法,可以解决【分类】&【回归】问题;
2.聚类---K-Means算法,属于无监督方法,解决电信用户分类问题;
3.统计学习---SVM(支持向量机)可以解决分类(主)和回归问题,有很好的表现和深厚的数学理论支撑,曾经被认为是最好的分类算法。现在光芒被【深度学习】掩盖了。有一定的数学门槛,面试中经常被问。
4.关联分析---Apriori应用于“尿片和纸尿裤”案例,最早解决了频繁项集问题。由于需要频繁访问数据库,已被淘汰。取代它的是华人开的【FP-Growth】算法。应用:电商的推荐系统,但目前有更好的替代方法。
5.统计分析---EM算法是一个算法框架,用于解决一系列问题。
6.连接挖掘---PageRank。Google使用的网页排序算法,很著名。
7.集装与推进---AdaBoosts算法,应用于人脸识别,本质为改进的决策树算法,属于有监督的分类算法。
8.分类---kNN。相对简单的分类算法,有监督。
9.分类---Naive Bayes朴素贝叶斯算法,用于识别垃圾邮件。
目前不常用的算法:Apriori和CART。
高阶算法:
FP-Growth---关联分析Apriori的改进版,华人发明的。
逻辑回归---推荐 搜索结果的排序。
RF随机森林---梯度提升决策树GBDT,与AdaBoost都属于对决策树的改进。
LDA---文本分析,自然语言处理。
Wod2Vector---文本挖掘,最终是一个结果。
HMM---隐马尔可夫模型,CRF条件随机场,自然语言处理,文本挖掘。
九.机器学习解决问题的框架
解决问题的框架:
1. 确定目标
业务需求:知道要做什么。
数据:学习的基础(数据可以直接就喂给算法,数据对模型的影响非常大,数据决定了最终的预测结果)
特征工程:数据预处理,提取特征 70%-数据的提取非常重要2. 训练模型(重点)
定义模型:确定算法。
定义损失函数:找出算法的偏差。
优化算法:对算法进行优化,让损失函数取最小
3. 模型评估
交叉验证:将不同的算法带入同一类数据中,验证效果。
效果评估:可以看出几个算法之间具体的差别、效果
查看全部 -
常见机器学习算法
 查看全部
查看全部 -
NoSQL 行为数据处理。
查看全部 -
利用计算机从历史数据中寻找规律,并把规律运用于未来的场景决策查看全部







举报