

-
Flink table 与sql的算子操作

 查看全部
查看全部 -
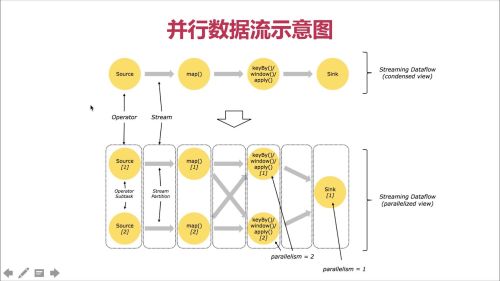
并行
 查看全部
查看全部 -
demo
查看全部 -
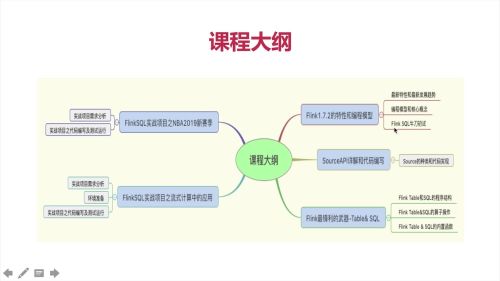
课程大纲
查看全部 -
随便写点啥
查看全部 -
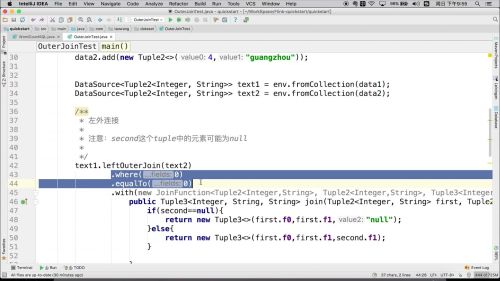
Flink Table & SQL API

 查看全部
查看全部 -
Flink Table & SQL
在Flink中,相等要使用三个 === 表示
 查看全部
查看全部 -
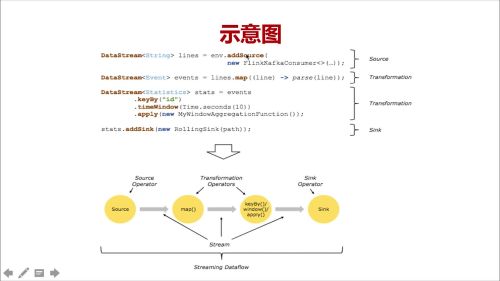
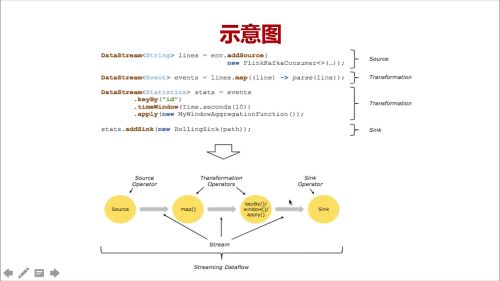
Flink 示意图
 查看全部
查看全部 -
Flink1.7.2新特性
(1)支持scala 2.12
(2) SQL 功能完善
(3)最新kafka连接器
(4)Streaming SQL新增Temporal Tables(时态表)
时态表:记录了数据发生该表的历史状态,该表可以返回特定时间点的表的内容
(5)Streaming SQL支持模式匹配
Flink CEP是Flink的复杂事件处理库,允许你在流上定义一系列的模式(pattern),最终使得你可以方便的抽取 自己需要的重要的事件处理。抽取自己需要的数据。
(6)Streaming SQL支持更多函数:REPLACE、REPEAT、LIRIM等函数
Blink 开源
阿里巴巴内部Flink 版本Blink已经开源,其最显著的特点就是强大的sql处理能力
查看全部 -
kafka
主题topic---消息分类
 查看全部
查看全部 -
查看消息队列中消息的列表
bin/kakfa-topics.sh --list --zookeeper localhost:2181
需求:有一个图书店铺,需要知道在促销期间每一本书买了多少


指定消费的位置,从哪里开始消费呢
consumer.setStartFromEarliest();
在上下文中设置source
env.addSource(consumer);

注册内存表

写sql

非常重要的知识点:回退更新:
tenv.toRetractStream(result,Row.class).print();
env.execute();
查看全部 -
FlinkSql实战项目之六十计算中的应用
kafka常用命令

创建消息
bin/kafka-topics.sh --create --zookeeper locahost:2181 --replication-factor 1 --partitions 1 --topic test2
启动生产者的客户端
bin/kafka-console-producer.sh --broker-list locahost:9092 --topic test2
启动消费者的客户端
bin/kafka-console-consumer.sh --bootstrao-server localhost:9092 --topic test2 --from-beginning
--from-beginning 从头开始消费消息队列中的数据
查看全部 -
定义数据结构
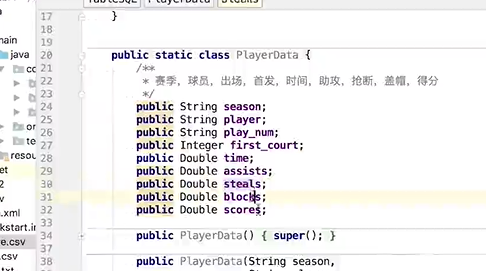
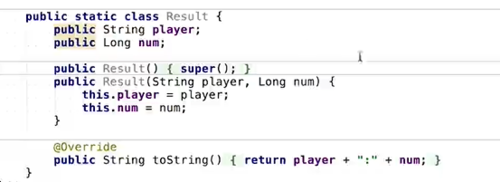
(1)获取上下文环境

(2)读取score.csv

(3)注册成内存表

(4)编写sql,然后提交执行

(5)结果进行打印
 查看全部
查看全部 -
NBA球星得分王排行榜
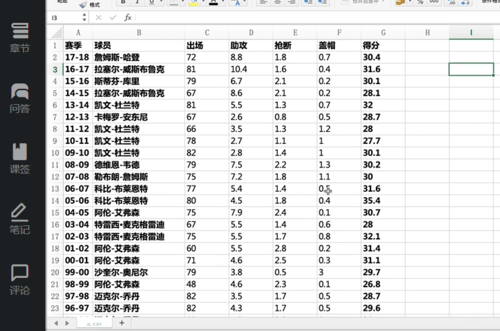
谁获得的得分王头衔最多
查看全部 -
自定义函数步骤
继承方法ScalarFunction
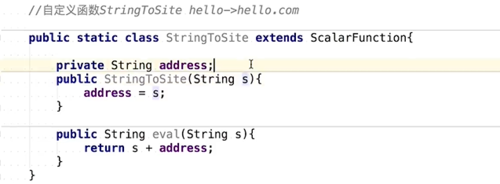
覆写方法Eval
注册函数

应用
 查看全部
查看全部 -
Flink提供了很多内置函数
(1)比较函数
(2)逻辑函数
(3)算数函数
(4)字符串处理函数
(5)时间函数
(6)其他
内置函数的演示没看
查看全部 -
Table和Sql的算子操作
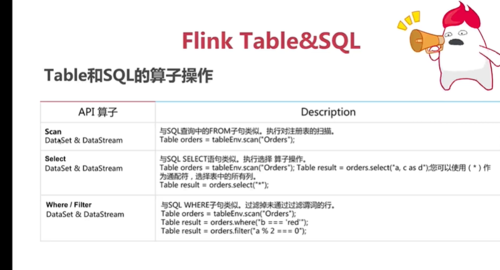
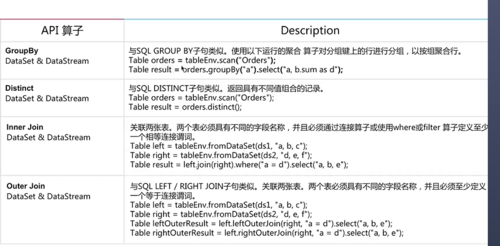 查看全部
查看全部 -
Flink Table&SQL的编程模型
 查看全部
查看全部 -
核心概念之并行度
Flink 是由多个任务组成(source、transformation和sink)。一个任务由多个并行的实例(线程)来执行,一个任务的并行实例(线程)数目就被称为该任务的并行度。
并行度的级别,4种
合理设置并行度能极大的提高运行速度
(1)算子级别 设置flink的编程API修改,通过调用方法的方式
(2)运行环境级别 设置executionEnvironmentk的方法修改并行度
(3)客户端级别 $FINK_HOME/bin/flink的-p参数,
(4)系统级别 修改$FLINK_HOME/conf/flink-conf.yaml文件
并行度的优先级:算子>运行环境>客户端>系统
注意:并行度不能大于Slot个数
TaskManager为了对资源进行隔离和增加允许的task数,引入了slot的概念,这个slot对资源的隔离仅仅是对内存进行隔离,策略是均分,比如taskmanager的管理内存是3GB,假如有两个个slot,那么每个slot就仅仅有1.5GB内存可用
查看全部 -
核心概念之时间
事件时间:是事件创建的事件。它通常由事件中的时间戳描述,例如kafka消息中的生成的时间戳
摄入时间:是事件进入Flink数据流运算符的时间
处理时间:是每一个执行时间操作的算符的本地时间
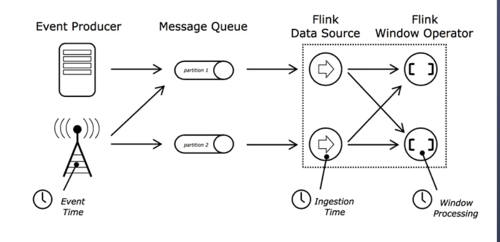 查看全部
查看全部 -
Flink1.7.2新特性
(1)支持scala 2.12
(2) SQL 功能完善
(3)最新kafka连接器
(4)Streaming SQL新增Temporal Tables(时态表)
时态表:记录了数据发生该表的历史状态,该表可以返回特定时间点的表的内容
(5)Streaming SQL支持模式匹配
Flink CEP是Flink的复杂事件处理库,允许你在流上定义一系列的模式(pattern),最终使得你可以方便的抽取 自己需要的重要的事件处理。抽取自己需要的数据。
(6)Streaming SQL支持更多函数:REPLACE、REPEAT、LIRIM等函数
Blink 开源
阿里巴巴内部Flink 版本Blink已经开源,其最显著的特点就是强大的sql处理能力
查看全部 -
flink 支持 Collection/本次文件的读写
查看全部 -
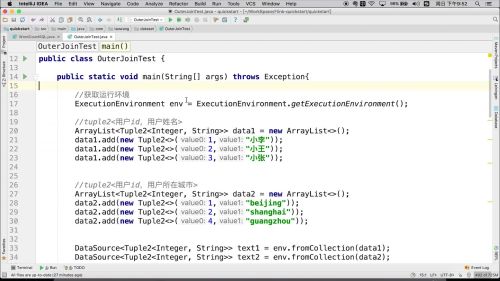
Tuple2<String,Integer> flink 特有的数据结构
防御性编程:确保代码的稳健性
查看全部 -
窗口模式图
查看全部 -
窗口模式处理
查看全部 -
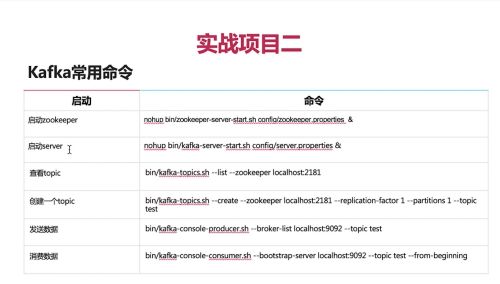
kafka常用命令
启动zookeeper
nohup bin/zookeeper -server-start.sh config/zookeeper.properties &
启动server
nohup /bin/kafka-server-start.sh config/server.properties &
查看topic
bin/kafa-topics.sh --list --zookeeper localhost:2181
创建一个topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
发送数据
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
消费数据
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
 查看全部
查看全部










举报