

-
shell命令操作HDFS:
通过shell命令对HDFS进行操作:与linux操作文件类似
通过python程序对HDFS进行操作
常用HDFS Shell命令:
1.类linux系统:ls、cat、mkdir、rm、chmod、chown等
2.HDFS文件交互:copyFromlocal、copyTplocal、get、put
查看全部 -
两个思考问题 :
1.数据块的大小设置为多少合适为什么?
hadoop数据块的大小一般设置为128M,如果数据块设置的太小,一般的文件也会被分割为多个数据块,在访问的时候需要查找多个数据块的地址,这样的效率很低,而且如果数据块设置太小的话,会消耗更多的NameNode的内存;而如果数据块设置过大的话,对于并行的支持不是太好,而且会涉及系统的其他问题,比如系统重启时,需要从新加载数据,数据块越大,耗费的时间越长。
2.NameNode有哪些容错机制,如果NameNode挂掉了怎么办?
NameNode容错机制,目前的hadoop2可以为之为HA(高可用)集群,集群里面有两个NameNode的节点,一台为主节点,一台为从节点,两者的数据时刻保持一致,当主节点出现问题时,从节点可以自动切换,用户基本感知不到,这样就避免了NameNode的单点问题。
HDFS写流程:
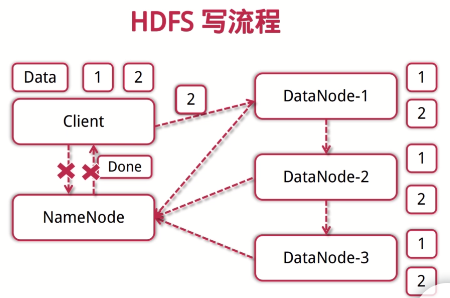
1.客户端向NameNode发起写数据
2.分块写入DataNode节点,DataNode自动完成副本备份
3.DataNode向NameNode汇报存储完成,NameNode通知客户端
HDFS读流程:
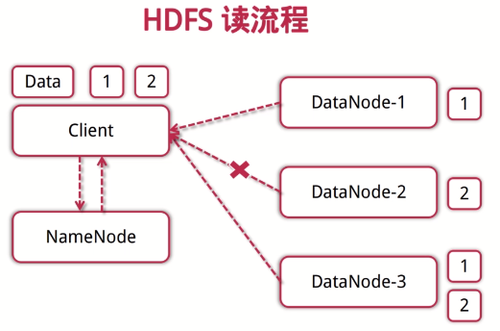
1.客户端向NameNode发起读数据的请求
2.NameNode找出最近的DataNode节点信息返回给客户端
3.客户端从DataNode分块下载文件
查看全部 -
Hadoop是什么:
1.Hadoop是一个开源框架
2.Hadoop是一个分布式计算的解决方案
3.Hadoop=HDFS(分布式文件系统)+MapReduce(分布式计算)
Hadoop的核心:
1.HDFS分布式文件系统:存储是大数据技术的基础
2.MapReduce编程模型:分布式 计算是大数据应用的解决方案
HDFS概念:
1.数据块
数据块是抽象块而非整个文件作为存储单元
默认大小为64MB,一般设置为128M,备份X3
2.NameNode
管理文件系统的命名空间,存放文件元数据
维系着文件系统的所有文件和目录,文件与数据块的映射
记录每个文件中各个块所在数据节点的信息
3.DataNode
存储并检索数据块
向NameNode更新所存储块的列表
HDFS优点:
1.适合大文件存储,支持TB,PB级的数据存储,并有副本策略
2.可以构建在廉价的机器上,并有一定的容错和恢复机制
3.支持流失数据访问,一次写入,多次读取最高效
HDFS缺点:
1.不适合大量小文件的存储
2.不适合并发的写入,不支持文件随机修改
3.不支持随机读等低延时的访问方式
两个思考问题 :
1.数据块的大小设置为多少合适为什么?
2.NameNode有哪些容错机制,如果 NameNode挂掉了怎么办?
查看全部 -
10.30,第二遍学习开始查看全部
-
大数据是一个概念也是一门技术,是在以Hadoop为代表的大数据平台框架上进行各种数据分析的技术。
大数据包括了以Hadoop和Spark为代表的基础大数据框架。
还包括实时数据处理,离线数据处理;数据分析,数据挖掘和用机器算法进行预测分析等技术。
查看全部 -
HDFS写流程
客户端向NameNode发起写数据请求。
分块写入DataNode节点,DataNode自动完成副本备份。
DataNode向NameNode汇报存储完成,NameNode通知客户端。
HDFS读流程
1.客户端向NameNode发起读数据请求。
2.NameNode找出距离最近的DataNode节点信息。
3.客户端从DataNode分块下载文件。
查看全部 -
Hadoop是什么?
Hadoop是一个开源的大数据框架。
hadoop是一个分布式计算的解决方案。
Hadoop = HDFS(分布式文件系统)+ MapReduce(分布式计算)。
Hadoop核心
1.HDFS分布式文件系统:存储是大数据技术的基础。
2.MapReduce编程模型:分布式计算是大数据应用的解决方案。
Hadoop基础架构
HDFS概念
1.数据块
2.NameNode(主)
1)管理文件系统的命名空间,存放文件元数据。
2)维护着文件系统的所有文件和目录,文件与数据块的映射。
3)记录每个文件中各个块所在数据节点的信息。
3.DataNode(从)
1)存储并检索数据块
2)向NameNode更新所存储块的列表。
HDFS的优点
1.适合大文件存储,支持TB、PB级的数据存储,并有副本策略。
2.可以构建在廉价的机器上,并且有一定的容错和恢复机制。
3.支持流式数据访问,一次写入,多次读取最高效。
HDFS缺点
1.不适合大量小文件存储。
2.不适合并发写入,不支持文件随机修改。
3.不支持随机读等低延时的访问方式。
查看全部 -
大数据是一个概念也是一门技术,是在以Hadoop为代表的大数据平台框架上进行各种数据分析的技术。
大数据包括了以Hadoop和spark为代表的基础大数据框架。
还包括实时数据处理,离线数据分析;数据分析,数据挖掘和用机器算法进行预测分析等技术。
查看全部 -
22222
查看全部 -
11111
查看全部 -
HDFS常用shell命令
查看全部 -
HDFS缺点
查看全部 -
DataNode
查看全部 -
namenode
查看全部 -
HDFS概念
查看全部





举报