

-
本地优化——Combine
数据经过Map端输出后会进行网络混洗,经Shuffle后进入Reduce,在大数据量的情况下可能会造成巨大的网络开销。故可以在不能低先按照key现行一轮排序与合并,再进行网络混洗,这个过程就是Combine。
在一个MapReduce作业中,Partitioner、reduce和最终输出文件的数量是总是相等的。
在一个Reducer中,所有数据都会被按照key值升序排序,故如果part输出文件中包含key值,则这个文件一定是有序的。
reduce任务的数量的最大值为72。通过调节参数mapred.reduce.tasks;可以在代码中调用job.setNumReduceTasks(int n)方法。
查看全部 -
Hadoop是一个分布式系统基础架构。具有高可靠性、高扩展性、高效性、高容错性、低成本。
HDFS,Hadoop分布式文件系统的简称。它所存放的每份文件可以有多个副本,所以HDFS是一个具有高冗余、高容错的文件系统。DataNode存放文件的单元为block。2.4以前,block的默认大小为64MB,2.6以后为128MB。
MapReduce是面向大数据并行处理的计算模型、框架和平台。一个基于集群的高性能并行计算平台;一个并行计算与运行软件框架;一个并行程序设计模型与方法。
yarn是hadoop的资源管理器,是一个通用资源管理系统。其中ResourceManager负责集群中所有资源的同一管理和分配,NodeManager管理Hadoop集群中单个计算节点。
查看全部 -
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。具有高可靠、高扩展、高有效、高容错、低成本。
HDFS,Hadoop分布式文件系统的简称。它所存放的每份文件可以有多个副本,所以HDFS是一个具有高冗余、高容错的文件系统。DataNode存放文件的单元为block。2.4以前,block的默认大小为64MB,2.6以后为128MB。
MapReduce是面向大数据并行处理的计算模型、框架和平台。一个基于集群的高性能并行计算平台;一个并行计算与运行软件框架;一个并行程序设计模型与方法。
yarn是hadoop的资源管理器,是一个通用资源管理系统。其中ResourceManager负责集群中所有资源的同一管理和分配,NodeManager管理Hadoop集群中单个计算节点。
查看全部 -
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。具有高可靠、高扩展、高有效、高容错、低成本。
HDFS,Hadoop分布式文件系统的简称。它所存放的每份文件可以有多个副本,所以HDFS是一个具有高冗余、高容错的文件系统。DataNode存放文件的单元为block。2.4以前,block的默认大小为64MB,2.6以后为128MB。
MapReduce是面向大数据并行处理的计算模型、框架和平台。一个基于集群的高性能并行计算平台;一个并行计算与运行软件框架;一个并行程序设计模型与方法。
yarn是hadoop的资源管理器,是一个通用资源管理系统。其中ResourceManager负责集群中所有资源的同一管理和分配,NodeManager管理Hadoop集群中单个计算节点。
查看全部 -
protected void map(LongWritable key,Text value Context context)
throws IOEception,InterruptedException{
//行
String row_matrix1 = value.toString().split("\t")[0];
//列_值(数组)
}
查看全部 -
Split Map Shuttle Reduce查看全部
-
老师讲的,清晰,透彻,不过需要自己实际操作一下,才能领会!
查看全部 -
二维向量的余玄相似度
查看全部 -
HDFS适合存放大文件
查看全部 -
ItemCF:基于物品的协同过滤推荐算法
查看全部 -
HDFS:分布式文件系统
DataNode:存放文件或文件副本。块:最小64MB。
查看全部 -
map查看全部
-
mapred.map.tasks 和 mapred.min.split.size设置Map任务数量的。
dfs.block.size可以调节块的大小。
查看全部 -
减少map的个数,合并小文件成大文件并压缩,在增大mapred.min.split.size的
查看全部 -
1. hadoop的分布式缓存及使用 2. 基于用户、物品和内容的协调过滤算法和实践 好东西查看全部
-
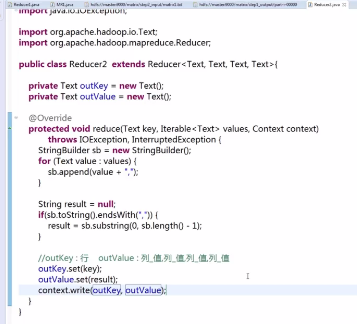
第二步编写的reducer类
查看全部 -
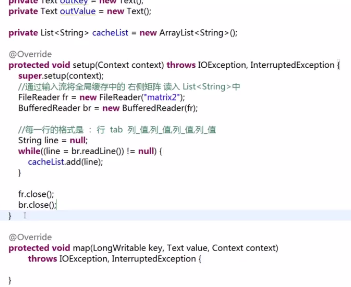
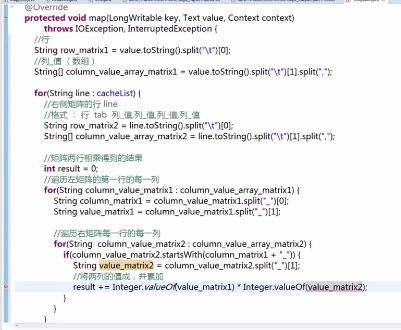
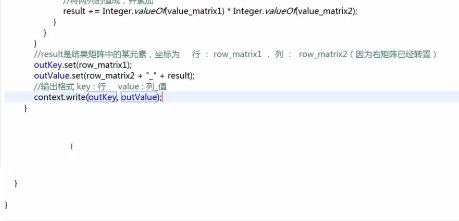
第二步编写的mapper类
查看全部










举报