

-
cdh版本稳定
查看全部 -
Hadoop生态圈
查看全部 -
再复习时,可只看最后一节课程总结查看全部
-
从2-3开始值得再看!查看全部
-
HBase的应用场景及特点
场景:交通,金融,电商,移动
1.海量数据存储(容量大);存储上百亿行*上百亿列
2.准实时查询
3.面向列(每一个列进行动态增加)
4.多版本:HBase每一个列的书库存储有多个Version
5.稀疏性:为空的列并不占存储空间
6.扩展性:底层依赖于HDFS
7.高可靠性:基于HDFS数据存储
8.高性能:底层的LSM数据结构和Rowkey有序排列等架构上的独特设计,使得Hbase具有非常高的写入性能
Hbase的概念与定位
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
[1] Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。

Hbase架构体系与设计模型:表数据;表结构
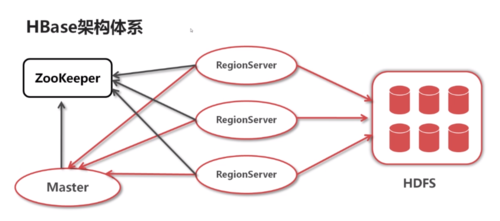
表结构:指定标的列簇(动态增加)
HBase的安装部署

HBase shell使用
查看全部 -
关系型数据库500万行,30列以下,hbase支持百亿行,百万列查看全部
-
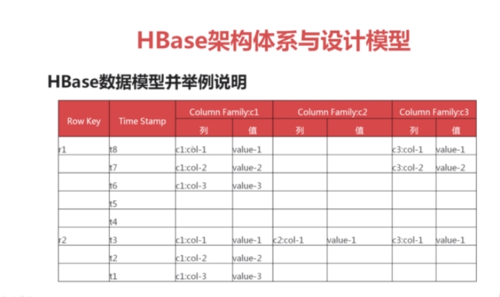
Hbase数据模型图
查看全部 -
HBase依赖
查看全部 -
HBbase是Hadoop2.x生态系统中唯一一个做真正的数据存储的工具
## HBase 周边生态
HBase 与 Hadoop 生态系统其他组件的关系非常紧密:
- HDFS 为 HBase 提供了高可靠性的底层存储支持。
- MapReduce 为 HBase 提供了高性能的计算能力。
- Zookeeper 为 HBase 提供了稳定性及 failover 机制的保障。
- Hive 可以与 HBase 相结合,使在 HBase 进行数据统计处理变得简单。
- Sqoop 为 HBase 提供了方便的 RDBMS 数据迁移功能
- Spark 等高性能的基于内存的分布式计算引擎也可能帮助我们更加快速的对 HBase 中的数据进行处理分析。查看全部 -
cloudera对相关工具做了整合,比如我们在下载hadoop和hbase的时候,选取相同cdh版本的下载,是更为稳妥的方式
查看全部 -
选取 CDH版本更为稳妥
查看全部 -
底层的LSM数据结构和Rowkey有序排序等设计,保证了高写入性能。
region切分、主键索引和缓存机制保证了hbase的随即读取性能。
查看全部 -
扩展性:依赖hdfs ,可以动态增加DataNode节点
查看全部 -
针对hbase数据库的稀疏性,非常好的对比描述
查看全部 -
为空的列不占用存储空间
查看全部 -
面向列的存储,列是可以动态增加的,并且列支持独立索引。
查看全部







举报