

-
hbase能做什么
1、海量数据存储
关系型数据库的字段一般在30内,超过则说明表的设计有问题,而hbase并没有列的限制(上百亿行、上百万列)
2、准实时查询
查看全部 -
课程目标
1、Hbase的应用场景及特点(为什么要学习这门技术,在业务场景中能够解决什么问题、提供什么样的服务)
2、habse架构体系与设计模型(架构体系:包含哪些进程、进程与进程之间的关系、Hbase服务于其他大数据服务之间的关系和依赖)(设计模型:hbase表结构的模型、表数据的模型)
查看全部 -
容量大
面向列
多版本
稀疏性,为空的列不占用存储空间
扩展性(底层依赖HDFS)
高可靠行(Replication以及底层的HDFS也有备份)
高性能(写:LSM数据结构;读:rowKey有序排列,region切分、主键索引和缓存机制)。
查看全部 -
Hbase与关系型数据库的对比
查看全部 -
海量数据查询:百亿行乘以百万列的数据量。mysql推荐千万行时进行分表。
准实时查询:查询速度百毫秒内。
查看全部 -
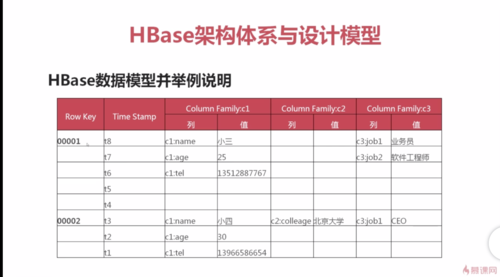
rowkey相当于表的行主键。timestamp是时间戳。Hbase是基于key-value形式的。所以在列簇内,每一列都有一个key和value。
列簇的注意事项:
1、一张表的列簇不会超过5个,超过5个会影响查询效率
2、每个列簇中的列数没有限制
3、列只有插入数据后才会存在,没插入数据不会占用磁盘空间
4、创建表只需要确定有多少个列簇即可,不需要创建列,列动态增加。
5、列在列簇中是有序的
Hbase和关系型数据库的对比:
Hbase表内的列是动态增加的,关系型数据库是不能动态增加。
Hbase表内的数据会自动切分,关系型数据库表内数据不会自动切分。当数据量很大是,关系型数据库要进行分库分表。
Hbase支持高并发读取,关系型数据库不支持,需要通过第三方插件、缓存来实现减少访问数据库。
Hbase不支持条件查询,只支持Rowkey查询,关系型数据库支持复杂查询。
查看全部 -
在创建Hbase表的时候,不需要创建列,只需要创建对应的列簇即可。列簇内的列的数量是可以设置超过上百万个的,列的个数不需要一开始就设定,可以后续动态增加。但是列簇建议不要多余5个。每个列簇,相当于一个分类。
查看全部 -
使用Hbase,需要先安装HDFS分布式文件系统和Zookeeper注册中心。
Hbase包括主进程master和多个regionServer子进程。
当表数据量很大的时候,可以对表进行分区,分成多个region。regionServer负责管理region.
regionServer会将分区的运行情况报告给master,方便master随时将宕机的region分配到其他的region。
regionServer也会将分区的运行情况报告给zookeeper。
查看全部 -
Hbase的应用场景:
查看全部 -
HBase 模型图
 查看全部
查看全部 -
HBase用途
查看全部 -
HBASE监控界面
查看全部 -
HBASE和关系数据库的区别
查看全部 -
Hadoop生态图
查看全部 -
在时间4.20 有各软件版本对应说明
查看全部







举报