

-
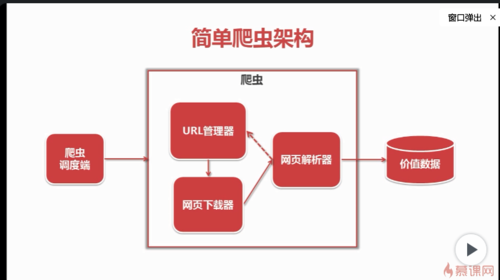
简单的爬虫架构
 查看全部
查看全部 -
 爬虫架构和三大模块查看全部
爬虫架构和三大模块查看全部 -
网页下载器 urllib2
查看全部 -
set 命令学习
set 能去除重复的数据
查看全部 -
分析目标:1、URL格式(页面的入口)
2、数据格式(要抓取的内容的数据格式,主要是查看他类和标签等)
3、网页编码(如UTF-8)
查看全部 -
1、4种解析器: 正则表达式、html.parser(python自带的)、Beautiful Soup(第三方插件)、lxml(第三方插件)
2、Beautiful Soup可以引用自带的html.parser及三方的lxml
3、正则表达式是进行模糊匹配的,其它三种都是结构化解析
4、结构化解析是采用了DOM(树形化结构来解析的)
查看全部 -
网页解析器
查看全部 -
简单爬虫架构
查看全部 -
urllib2下载网页方法3
查看全部 -
urllib2下载网页方法2
查看全部 -
网页下载器urllib2下载网页的方法1
查看全部 -
python的两种网页下载器
内置的urllib2
第三方的requests
查看全部 -
网页下载器
将互联网上url对应的网页内容下载到本地
保存成文件或者内存字符串
查看全部 -
url管理器的实现方式
内存 python的 set()
关系数据库 MySQL
缓存数据库 Redis
查看全部 -
url管理器的功能
查看全部





举报
0/150
提交
取消