

-
网页解析器
查看全部 -
Python 3:
# coding:utf-8
import urllib
from http import cookiejar
url = "http://www.baidu.com"
print("第一种方法")
response1 = urllib.request.urlopen(url)
print(response1.getcode())
print(len(response1.read()))
print("第二种方法")
request = urllib.request.Request(url)
request.add_header("user-agent", "Mozilla/5.0")
response2 = urllib.request.urlopen(url)
print(response2.getcode())
print(len(response2.read()))
print("第三种方法")
cj= cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
urllib.request.install_opener(opener)
response3 = urllib.request.urlopen(url)
print(response3.getcode())
print(cj)
print(len(response3.read()))查看全部 -
urllib2下载网页方法3:添加特殊情景的处理器查看全部
-
urllib2下载网页方法2
查看全部 -
两个网页下载器
查看全部 -
URL管理器的三种方式
查看全部 -
urllib2下载网页方法1:最简洁方法
查看全部 -
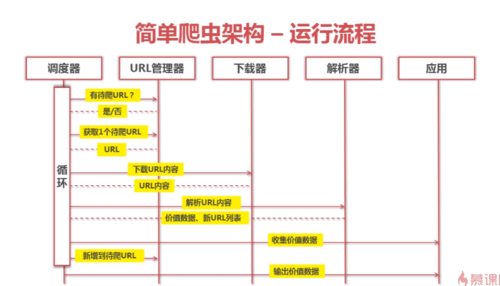
简单爬虫结构-运行流程
查看全部 -
简单爬虫结构
查看全部 -
URL管理器实现方式
查看全部 -
简单爬虫架构 运行流程
查看全部 -
网页下载器:将互联网上url对应的网页下载的本地的工具
urllib2:python官方基础模块,支持登录的cookie ,代理处理
requests第三方包更强大
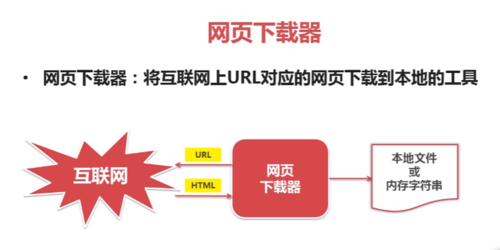 查看全部
查看全部 -
URL管理器-实现方式
set 命令学习
set 能去除重复的数据
查看全部 -
url管理器
 查看全部
查看全部 -
简单爬虫架构-运行流程
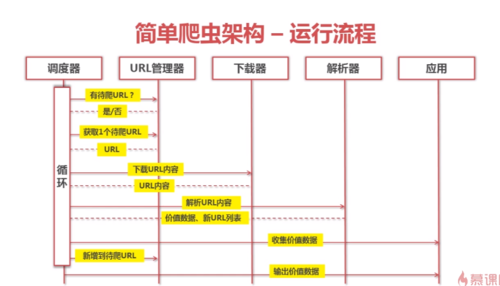 查看全部
查看全部



举报