

-
itemcf:用户数量远小于物品数量,物品丰富个性化需求强烈
查看全部 -
itemcf/usercf
点击物品立即更新
不能及时推荐新物品
推荐理由更信服
查看全部 -
第一部分:召回(用户行为数据)
第二部分:排序
第三部分:策略调整
查看全部 -
学习中查看全部
-
P_u_i为user_u对item_i的感兴趣程度:
user_v是和user_i最相似的topk用户
item_i是user_v行为过但是user_u没有行为过的item
r_v_i表示user_v对item_i的行为得分
查看全部 -
s_i_j表示 i和j的相似度,
r_u_i表示u对item_i的行为得分
对user进行item_j的推荐的得分:
基于item_i做推荐,item_i是用户行为过得商品,
选取与item_i 最相似的top_k个商品,一般k选取50个。
举例:
用户购买了cherry机械键盘并给了差评,此时的r_u_i可能就0.1分
用户又购买了了雷蛇键盘并给了好评, 此时r_u_i可能就为0.8分
用户还购买了雷蛇鼠标垫并给了好评, 此时r_u_i可能为0.7分
此时用户对雷蛇鼠标感兴趣程度:
p_u_j = 0.3[cherry键盘]*0.1 + 0.4[雷蛇键盘]*0.8 + 0.6[雷蛇鼠标垫]*0.7
查看全部 -
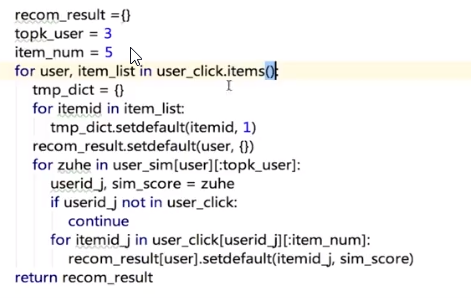
def cal_recom_result(user_click,user_sim) #revise
 查看全部
查看全部 -
def main_flow
 查看全部
查看全部 -
def cal_recom_result(user_click,user_sim)
 查看全部
查看全部 -
def cal_user_sim(item_click_by_user) # part2
查看全部 -
def cal_user_sim(item_click_by_user) # part1
查看全部 -
def transfer_user_click(user_click)
 查看全部
查看全部 -
个性化推荐算法实战第01章个性化推荐算法综述
1、什么是推荐系统?
在介绍推荐算法之前需要先介绍一下什么是信息过载。
信息过载就是信息的数量远超于人手工可以遍历的数量。比如,当你没有目的性的去逛超市,你不可能把所有的商品都看一遍都有什么。同样,无论是去书店看书,还是在电影网站上搜索电影,这些物品的量级对于没有目的性、需求性的用户而言都是信息过载。
那么什么是推荐系统呢?
就是当用户的目的不明确、且该服务对于用户而言构成了信息过载;但该系统基于一定的策略规则,将物品进行了排序,并将前面的物品展示给了用户,这样的系统就可以称之为推荐系统。
举例说明,在网站购物过程中,无论是天猫或者京东这样的平台,如果我们有明确的需求去搜索框里检索。如希望买啤酒,那么检索结果就是很多种类的啤酒;如果没有明确的需求,就会有猜你喜欢等等模块,这些模块就是推荐系统基于一定的规则策略计算出来的,这些规则策略就是个性化推荐算法。
2、个性化推荐算法在系统中所起到的作用
推荐系统在工业界落地较成功的三大产品:电商、信息流、地图基于位置服务的(LBS)的推荐
推荐系统如今在工业界中落地较为成功的有三类产品,分别是电商、地图、基于LBS的推荐。电商中,用户需要面对数以十万计的新闻与短视频,地图中用户需要面对数以百万计的餐馆等等;但是用户首先看到的都不会是全部的内容,只会是几个或者几十个新闻、短视频、餐馆等等,决定从物品海洋里选择哪些展现给用户的就是个性化推荐算法。
如果推荐的精确,也就是说该推荐系统推荐的恰好是用户想要的、或者是促进了用户的需求,那么就会推动用户在该电商上进行消费、停留、阅读等等。所以,在推荐系统中最为重要的就是个性化推荐算法。
3、如何衡量个性化推荐算法在产品中起到的作用
分为线上和线下两个部分。其中线下部分主要依托于模型本身的评估指标,比如个性化召回算法中模型的准确率等等;在线上,基于业务本身的核心指标,比如基于信息流产品中的平均阅读时长等等。
信息流中的点击率 ctr 与停留时长 dwell time
电商中的GMV(Gross Merchandise Volume,网站成交金额)
4、推荐算法介绍
包括:个性化召回算法、个性化排序算法

5、评估指标:
包括:在线评估指标和离线评估指标
个性化召回
1、什么是个性化召回?
在item全集中选取一部分作为候选集。
这里就存在一个问题,就是说为什么要选取一部分作为作为候选集,而不是全部?其原因在于:1.不同的用户不会喜欢所有类型的item;2.基于服务性能的考虑,如果选择了全部的item作为候选集,对于后续的排序就将耗费大量的时间,对于整体推荐的后端,服务响应时间将会是灾难性的。
根据用户的属性行为上下文等信息从物品全集中选取其感兴趣的物品作为候选集。
下面举例说明:
如果某个推荐系统中,物品全集是如下左图中9个item,这里有两个用户A和B,他们分别对不同的item感兴趣。这里拿信息流产品举例,如果user A对体育类新闻感兴趣,user B对娱乐类新闻感兴趣,那就按照简单的类别召回,得到结果如下右图所示。
在候选集{a,b,c,....,g,h,i}中为User A,User B选取一部分item作为候选集。
2、召回的重要作用
1、召回决定了最终推荐结果的天花板
为什么这么说呢?这里先看一下推荐系统的整体架构,工业中的个性化推荐系统中的策略部分的架构主要由一下三部分构成:召回、排序、以及最后的策略调整部分,其中召回部分包括各路个性化召回之后将所有的item merge进入rank部分,rank只是调整召回完item的展现顺序,rank完之后还有一些策略的调整,比如信息流场景中的控制相同作者的数目等等,所以可以看到个性化召回的候选集是多么的重要,因为最终展现给用户的就是从这个候选集中选出来的。那么就可能会有疑问,为什么不能将所有的item进行排序?这是为了保证后端响应时间。
与用户离的最近的是端,在移动互联网的时代主要的流量集中在了移动app也可以是网站前端。连接接前后端的是WEB API层。WEB层主要给APP端提供API服务,解析端上发来的请求,调用后端rpc服务。得到的结果投全到端上。web api层尽量不做策略业务逻辑,但是会做一些诸如log写实时信息队列,或写分布式存储这样的事情来方便后续的数据分析和模型训练。
最后是后端的RPC服务。个性化推荐算法主要发挥作用的部分。
RPC服务的三大策略部分。
第一:个性化召回,基于用户的行为,通过算法模型来为用户精准推荐。或基于用户画像的标签推荐同类型的item。举个栗子,如果某个用户过往经常点击体育类的item,那么用户画像就给她标上体育的lable。那么有较新的体育类新闻,会优先推荐给改用户。召回决定了最终推荐结果的天花板,因为这一步决定了候选集。
第二部分:排序部分。第一部分召回了用户感兴趣的物品集合后,我们需要决策 出展现给用户的顺序。好的顺序可以让用户在列表的开始找到自己的所需,完成转化。因为用户的每一次下拉都是有成本的,如何不能在最初的几屏里,显示用户的所需,用户就很可能流失掉。结合刚才召回所举的例子,给用户召回了体育类的item,不同的item可能会有不同的浏览人数,评论人数,发布时间,不同的字数,不同的时长,不同的发布时间等等,同样该用户也有体育类的细分的倾向性。
第三部分:策略调整部分,基于业务场景的策略调整部分。由于召回和排序大多数是基于模型来做的,所以基于业务场景的策略调整部分可以增加一些规则来fit业务场景。比如在信息流场景中,我们不希望给用户一直连续推荐同一个作者的新闻,我们可以加一些打散的策略。
2、个性化召回解析
个性化召回算法分为哪几大类?
基于用户行为的(也就是用户基于推荐系统推荐给他的item点击或者没点。)
CF(基于邻域的算法:user CF item CF)、矩阵分解、基于图的推荐(graph-based model)——基于图的随机游走算法:PersonalRank
这一类的个性化召回算法总体来说就是推荐结果的可解释性较强,比较通俗易懂,但是缺少一些新颖性。
基于user profile的
经过用户的自然属性,也就是说经过用户的偏好统计,那么基于这个统计的类别去召回。推荐效果不错,但是可扩展性较差。也就是说一旦用户被标上了某一个类别或者某几个类别的标签之后,很难迁移到其余的一些标签。
基于用户的偏好的统计的类别类召回。效果不错,可扩展性比较差。
隐语义模型Latent Factorization Model(LFM)
新颖性、创新性十足,但是可解释性不是那么强。
3、工业界个性化召回架构
整体的召回架构可以分为两大类:
第一大类是离线模型。根据用户行为基于离线的model file算出推荐结果,这些推荐结果可以是用户喜欢哪些item集合,也可以是item之间的相似度文件 ,计算出具有某种lable的item的排序。然后离线计算好的排序的文件写入KV存储。在用户访问服务的时候,Recall部分直接从KV中读取。因为我们直接存储的是item ID,我们读取到的item id的时候还需要去Detail Server中得到每个item id的详情,然后将详情拼接好传给rank。(在线的server recall部分直接调用这个结果,拿到ID之后访问detail server得到详情,再往rank部分传递)
第二大类是深度学习模型,如果采用深度学习的一些model,这是需要将model file算出来的item embedding的向量也需要离线存入KV中,但是用户在访问我们的KV的时候,在线访问深度学习模型服务(recall server)的User embedding。同时去将user embedding层的向量和item embedding层的向量做最近邻计算,并得到召回。
https://blog.csdn.net/qintian888/article/details/95945527
查看全部






举报