
前言
大家好,我是小彭。
今天分享到一种栈的衍生数据结构 —— 单调栈(Monotonic Stack)。栈(Stack)是一种满足后进先出(LIFO)逻辑的数据结构,而单调栈实际上就是在栈的基础上增加单调的性质(单调递增或单调递减)。那么,单调栈是用来解决什么问题的呢?
学习路线图:

1. 单调栈的典型问题
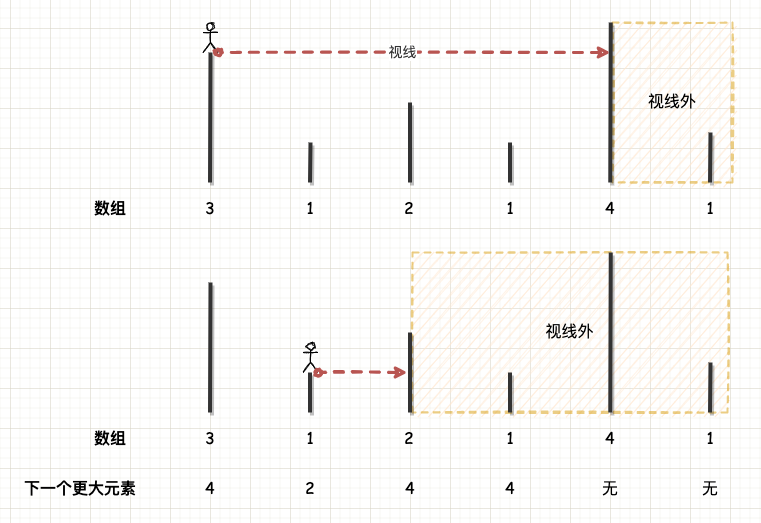
单调栈是一种特别适合解决 “下一个更大元素” 问题的数据结构。
举个例子,给定一个整数数组,要求输出数组中元素 iii 后面下一个比它更大的元素,这就是下一个更大元素问题。这个问题也可以形象化地思考:站在墙上向后看,问视线范围内所能看到的下一个更高的墙。例如,站在墙 [3] 上看,下一个更高的墙就是墙 [4] 。
形象化思考
这个问题的暴力解法很容易想到:就是遍历元素 iii 后面的所有元素,直到找到下一个比 iii 更大的元素为止,时间复杂度是 O(n)O(n)O(n),空间复杂度是 O(1)O(1)O(1)。单次查询确实没有优化空间了,那多次查询呢?如果要求输出数组中每个元素的下一个更大元素,那么暴力解法需要的时间复杂度是 O(n2)O(n^2)O(n2) 。有没有更高效的算法呢?
2. 解题思路
我们先转变一下思路:
在暴力解法中,我们每处理一个元素就要去求它的 “下一个更大元素”。现在我们不这么做,我们每处理一个元素时,由于不清楚它的解,所以先将它缓存到某种数据容器中。后续如果能确定它的解,再将其从容器中取出来。 这个思路可以作为 “以空间换时间” 优化时间复杂度的通用思路。
回到这个例子上:
-
在处理元素
[3]时,由于不清楚它的解,只能先将[3]放到容器中,继续处理下一个元素; -
在处理元素
[1]时,我们发现它比容器中所有元素都小,只能先将它放到容器中,继续处理下一个元素; -
在处理元素
[2]时,我们观察容器中的[1]比当前元素小,说明当前元素就是[1]的解。此时我们可以把[1]弹出,记录结果。再将[2]放到容器中,继续处理下一个元素; -
在处理元素
[1]时,我们发现它比容器中所有元素都小,只能先将它放到容器中,继续处理下一个元素; -
在处理元素
[4]时,我们观察容器中的[3][2][1]都比当前元素小,说明当前元素就是它们的解。此时我们可以把它们弹出,记录结果。再将[4]放到容器中,继续处理下一个元素; -
在处理元素
[1]时,我们发现它比容器中所有元素都小,只能先将它放到容器中,继续处理下一个元素; -
遍历结束,所有被弹出过的元素都是有解的,保留在容器中的元素都是无解的。
分析到这里,我们发现问题已经发生转变,问题变成了:“如何寻找在数据容器中小于当前元素的数”。 现在,我们把注意力集中在这个容器上,思考一下用什么数据结构、用什么算法可以更高效地解决问题。由于这个容器是我们额外增加的,所以我们有足够的操作空间。
先说结论:
- 方法 1 - 暴力: 遍历整个数据容器中所有元素,最坏情况(递减序列)下所有数据都进入容器中,单次操作的时间复杂度是 O(N)O(N)O(N),整体时间复杂度是 O(N2)O(N^2)O(N2);
- 方法 2 - 二叉堆: 不需要遍历整个容器,只需要对比容器的最小值,直到容器的最小值都大于当前元素。最坏情况(递减序列)下所有数据都进入堆中,单次操作的时间复杂度是 O(lgN)O(lgN)O(lgN),整体时间复杂度是 KaTeX parse error: Expected 'EOF', got '·' at position 4: O(N·̲lgN);
- 方法 3 - 单调栈: 我们发现元素进入数据容器的顺序正好是有序的,且后进入容器的元素会先弹出做对比,符合 “后进先出” 逻辑,所以这个容器数据结构用栈就可以实现。因为每个元素最多只会入栈和出栈一次,所以整体的计算规模还是与数据规模成正比的,整体时间复杂度是 O(n)O(n)O(n)。
下面,我们先从优先队列说起。
3. 优先队列解法
寻找最值的问题第一反应要想到二叉堆。
我们可以维护一个小顶堆,每处理一个元素时,先观察堆顶的元素:
- 如果堆顶元素小于当前元素,则说明已经确定了堆顶元素的解,我们将其弹出并记录结果;
- 如果堆顶元素不小于当前元素,则说明小顶堆内所有元素都是不小于当前元素的,停止观察。
观察结束后,将当前元素加入小顶堆,堆会自动进行堆排序,堆顶就是整个容器的最小值。此时,继续在后续元素上重复这个过程。
题解
fun nextGreaterElements(nums: IntArray): IntArray {
// 结果数组
val result = IntArray(nums.size) { -1 }
// 小顶堆
val heap = PriorityQueue<Int> { first, second ->
nums[first] - nums[second]
}
// 从前往后查询
for (index in 0 until nums.size) {
// while:当前元素比堆顶元素大,说明找到下一个更大元素
while (!heap.isEmpty() && nums[index] > nums[heap.peek()]) {
result[heap.poll()] = nums[index]
}
// 当前元素入堆
heap.offer(index)
}
return result
}
我们来分析优先队列解法的复杂度:
- 时间复杂度: 最坏情况下(递减序列),所有元素都被添加到优先队列里,优先队列的单次操作时间复杂度是 O(lgN)O(lgN)O(lgN),所以整体时间复杂度是 KaTeX parse error: Expected 'EOF', got '·' at position 4: O(N·̲lgN);
- 空间复杂度: 使用了额外的优先队列,所以整体的空间复杂度是 O(N)O(N)O(N)。
优先队列解法的时间复杂度从 O(N2)O(N^2)O(N2) 优化到 KaTeX parse error: Expected 'EOF', got '·' at position 4: O(N·̲lgN),还不错,那还有优化空间吗?
4. 单调栈解法
我们继续分析发现,元素进入数据容器的顺序正好是逆序的,最后加入容器的元素正好就是容器的最小值。此时,我们不需要用二叉堆来寻找最小值,只需要获取最后一个进入容器的元素就能轻松获得最小值。这符合 “后进先出” 逻辑,所以这个容器数据结构用栈就可以实现。
这个问题也可以形象化地思考:把数字想象成有 “重量” 的杠铃片,每增加一个杠铃片,会把中间小的杠铃片压扁,当前的大杠铃片就是这些被压扁杠铃片的 “下一个更大元素”。
形象化思考

解题模板
// 从前往后遍历
fun nextGreaterElements(nums: IntArray): IntArray {
// 结果数组
val result = IntArray(nums.size) { -1 }
// 单调栈
val stack = ArrayDeque<Int>()
// 从前往后遍历
for (index in 0 until nums.size) {
// while:当前元素比栈顶元素大,说明找到下一个更大元素
while (!stack.isEmpty() && nums[index] > nums[stack.peek()]) {
result[stack.pop()] = nums[index]
}
// 当前元素入队
stack.push(index)
}
return result
}
理解了单点栈的解题模板后,我们来分析它的复杂度:
- 时间复杂度: 虽然代码中有嵌套循环,但它的时间复杂度并不是 O(N2)O(N^2)O(N2),而是 O(N)O(N)O(N)。因为每个元素最多只会入栈和出栈一次,所以整体的计算规模还是与数据规模成正比的,整体时间复杂度是 O(N)O(N)O(N);
- 空间复杂度: 最坏情况下(递减序列)所有元素被添加到栈中,所以空间复杂度是 O(N)O(N)O(N)。
这道题也可以用从后往前遍历的写法,也是参考资料中提到的解法。 但是,我觉得正向思维更容易理解,也更符合人脑的思考方式,所以还是比较推荐小彭的模板(王婆卖瓜)。
解题模板(从后往前遍历)
// 从后往前遍历
fun nextGreaterElement(nums: IntArray): IntArray {
// 结果数组
val result = IntArray(nums.size) { -1 }
// 单调栈
val stack = ArrayDeque<Int>()
// 从后往前查询
for (index in nums.size - 1 downTo 0) {
// while:栈顶元素比当前元素小,说明栈顶元素不再是下一个更大元素,后续不再考虑它
while (!stack.isEmpty() && stack.peek() <= nums[index]) {
stack.pop()
}
// 输出到结果数组
result[index] = stack.peek() ?: -1
// 当前元素入队
stack.push(nums[index])
}
return result
}
5. 典型例题 · 下一个更大元素 I
理解以上概念后,就已经具备解决单调栈常见问题的必要知识了。我们来看一道 LeetCode 上的典型例题:LeetCode 496.
LeetCode 例题

第一节的示例是求 “在当前数组中寻找下一个更大元素” ,而这道题里是求 “数组 1 元素在数组 2 中相同元素的下一个更大元素” ,还是同一个问题吗?其实啊,这是题目抛出的烟雾弹。注意看细节信息:
- 两个没有重复元素的数组
nums1和nums2; nums1是nums2的子集。
那么,我们完全可以先计算出 nums2 中每个元素的下一个更大元素,并把结果记录到一个散列表中,再让 nums1 中的每个元素去散列表查询结果即可。
题解
class Solution {
fun nextGreaterElement(nums1: IntArray, nums2: IntArray): IntArray {
// 临时记录
val map = HashMap<Int, Int>()
// 单调栈
val stack = ArrayDeque<Int>()
// 从前往后查询
for (index in 0 until nums2.size) {
// while:当前元素比栈顶元素大,说明找到下一个更大元素
while (!stack.isEmpty() && nums2[index] > stack.peek()) {
// 输出到临时记录中
map[stack.pop()] = nums2[index]
}
// 当前元素入队
stack.push(nums2[index])
}
return IntArray(nums1.size) {
map[nums1[it]] ?: -1
}
}
}
6. 典型例题 · 下一个更大元素 II(环形数组)
第一节的示例还有一道变型题,对应于 LeetCode 上的另一道典型题目:503. 下一个更大元素 II
LeetCode 例题

两道题的核心考点都是 “下一个更大元素”,区别只在于把 “普通数组” 变为 “环形数组 / 循环数组”,当元素遍历到数组末位后依然找不到目标元素,则会循环到数组首位继续寻找。这样的话,除了所有数据中最大的元素,其它每个元素都必然存在下一个更大元素。
其实,计算机中并不存在物理上的循环数组,在遇到类似的问题时都可以用假数据长度和取余的思路处理。如果你是前端工程师,那么你应该有印象:我们在实现无限循环轮播的控件时,有一个小技巧就是给控件 设置一个非常大的数据长度 ,长到永远不可能轮播结束,例如 Integer.MAX_VALUE。每次轮播后索引会加一,但在取数据时会对数据长度取余,这样就实现了循环轮播了。
无限轮播伪代码
class LooperView {
private val data = listOf("1", "2", "3")
// 假数据长度
fun getSize() = Integer.MAX_VALUE
// 使用取余转化为 data 上的下标
fun getItem(index : Int) = data[index % data.size]
}
回到这道题,我们的思路也更清晰了。我们不需要无限查询,所以自然不需要设置 Integer.MAX_VALUE 这么大的假数据,只需要 设置 2 倍的数据长度 ,就能实现循环查询(3 倍、4倍也可以,但没必要),例如:
题解
class Solution {
fun nextGreaterElements(nums: IntArray): IntArray {
// 结果数组
val result = IntArray(nums.size) { -1 }
// 单调栈
val stack = ArrayDeque<Int>()
// 数组长度
val size = nums.size
// 从前往后遍历
for (index in 0 until nums.size * 2) {
// while:当前元素比栈顶元素大,说明找到下一个更大元素
while (!stack.isEmpty() && nums[index % size] > nums[stack.peek() % size]) {
result[stack.pop() % size] = nums[index % size]
}
// 当前元素入队
stack.push(index)
}
return result
}
}
7. 总结
到这里,相信你已经掌握了 “下一个更大元素” 问题的解题模板了。除了典型例题之外,大部分题目会将 “下一个更大元素” 的语义隐藏在题目细节中,需要找出题目的抽象模型或转变思路才能找到,这是难的地方。
小彭在 20 年的文章里说过单调栈是一个相对冷门的数据结构,包括参考资料和网上的其他资料也普遍持有这个观点。 单调栈不能覆盖太大的问题域,应用价值不及其他数据结构。 —— 2 年前的文章
2 年后重新思考,我不再持有此观点。我现在认为:单调栈的关键是 “单调性”,而栈只是为了配合问题对操作顺序的要求而搭配的数据结构。 我们学习单调栈,应该当作学习单调性的思想在栈这种数据结构上的应用,而不是学习一种新的数据结构。对此,你怎么看?
共同学习,写下你的评论
评论加载中...
作者其他优质文章


