
鱼羊 发自 凹非寺
量子位 报道
所谓因果,作为一个人类,你肯定并不陌生。
银杏叶黄了,是因为寒露已至。你的肚子开始咕咕叫,是因为晚饭时间到了。

因果推理这个词看上去并不日常,但事实上,这是人类在与现实世界进行交互时必不可少的能力。
对于AI来说,因果推理能力同样很重要。随着深度学习模型在各个领域取得巨大成功,其缺失因果推理能力的问题也逐渐暴露。没有正确的因果模型,这些机器学习方法的泛化就很成问题,比如,给图像生成说明的模型有时候会生成一些脱离实际的说明文字。
如此AI,显得很不智能。
图灵奖得主Judea Pearl就曾指出,机器学习的突破口在于“因果革命”。

现在,李飞飞团队带来了他们在因果推理方面的最新研究:
让人工智能在视觉观察中逐步生成因果图,并有选择性地根据诱导图来决定行动。
所以,他们是怎么样赋予AI因果推理的能力的呢?
两个阶段
对于AI而言,因果归纳和推理是两个不同的阶段。
比如说,进入一个有许多灯的陌生房间,在不事先了解布线的情况下,想要开灯,就得先试试各个开关,理清开关和灯之间的对应关系。
AI触发开关的第一阶段,就是因果归纳。在这一阶段,智能体通过执行动作并观察结果,来发现潜在的因果关系。
第二阶段是因果推理,智能体使用已获得的因果关系来决定行动,以完成任务。
为了建立有效的因果归纳和推理计算模型,必须在测试时完成对新的因果关系和新任务目标的概括。
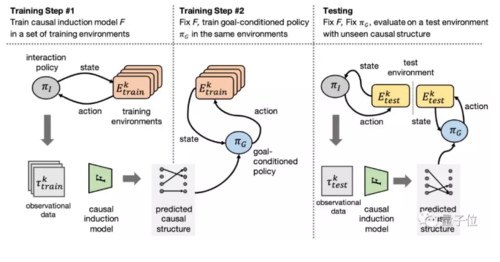
第一阶段,李飞飞团队采用因果归纳模型,根据智能体的观察数据构建因果结构,即随机变量的有向无环图。
这里采用的新技术,是迭代因果归纳网络。
迭代因果归纳网络
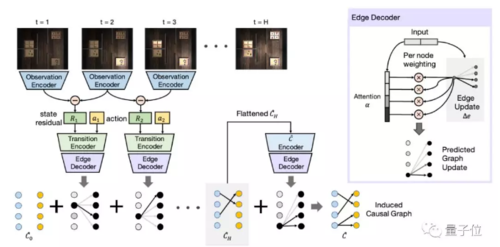
从原始的感官观察中归纳出因果结构,需要准确地捕捉每个行为对环境的独特影响,同时考虑其他行为的混杂影响。
研究团队假设,最能概括因果关系的归纳网络将是一个能分解单个动作及其对应效果的网络,并且只更新因果图的相关成分。
在迭代模型中,首先假设因果结构的边缘权重为0(即没有因果关系),并将观测数据的每个帧映射到一个编码。
然后,计算跨时间步长的状态嵌入之间的差异(即,状态残差),并将其与相应的动作关联起来。
这些数据被喂给边缘解码器模块(the Edge Decoder),该模块负责预测边缘更新,以及用于衡量边缘更新如何应用于节点的注意力向量。
最后,应用基于当前图的更多边缘更新,并输出最终的预测图。
第二阶段,使用因果结构将目标条件策略置于背景之中,以执行指定目标的任务。因果结构的构造是显式的,这样,在long-horizon任务中,新的问题实例能更好地泛化。
研究团队提出了基于注意力的图编码的目标条件策略(goal-conditioned policy)。
学习目标条件策略
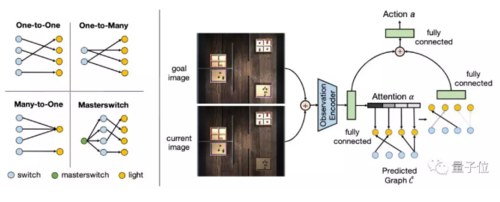
这一策略的目的是给定一个初始图像,一个目标图像,以及预测的因果结果,在规定时间步长内完成既定目标。
输入数据是当前图像,目标图像和预测因果图。假设最佳策略专注于学习因果图中与当前任务步骤相关的边缘。
将当前图像和目标图像进行编码。基于这一编码,输出因果图中“效果”上的注意力向量,从而提取相关边缘。然后,将其与图像编码对应起来,预测最终动作。
实验
新方法效果如何,还是要用实验说话。
迭代因果归纳网络(ICIN)的比较对象,是使用时间卷积的非迭代归纳模型(TCIN)和不带注意力机制的ICIN。
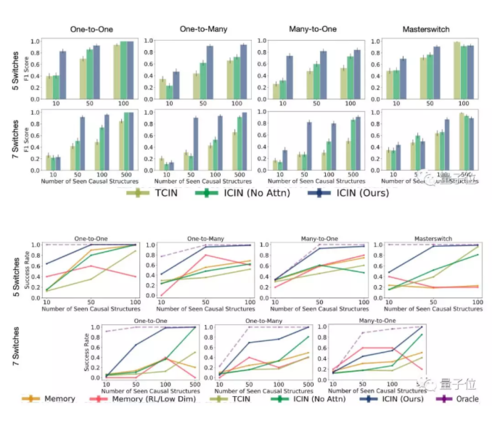
在绝大部分实验条件之下,李飞飞团队的方法(蓝条)都要优于对照组。
One More Thing
学会因果推理的AI,有什么用呢?
李飞飞团队曾经造出这样一只AI,能“窥见未来”。
一个人从车后绕来,他是谁?要去哪儿?想干什么?

这只AI不仅“预知”了线路,还答出了“开门”这个正确答案。
对于人类而言,做出这样的预测并不难,以特定目的为导向,了解一个人的目的,就能推测他要去哪儿要做什么。
同样,对于AI而言,学会了因果推理,在完成目标导向任务时,就能事半功倍。
李飞飞团队
论文一作,是斯坦福在读博士Suraj Nair,曾在谷歌大脑实习。

他师从Silvio Savarese教授,也就是李飞飞的丈夫。

论文的另一位作者是Yuke Zhu是斯坦福SVL实验室(Stanford Vision and Learning Lab)的一员,该实验室由李飞飞,Silvio Savarese和Juan Carlos Niebles主导。
Yuke Zhu今年8月刚从斯坦福博士毕业,将于2020年秋季入职德州大学奥斯汀分校。

李飞飞和她的丈夫Silvio Savarese为论文的另外两名作者。
论文地址:
https://arxiv.org/abs/1910.01751
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
共同学习,写下你的评论
评论加载中...
作者其他优质文章



