我将从头开始,因为我觉得我迷失了所有不同的可能性。我将讨论的是排行榜,但也适用于价格跟踪。我的目标是从网站(所有时间排行榜/隐藏)中抓取数据,将其放入 .csv 文件中并每天中午更新。到目前为止我所取得的成功:抓取数据。尝试使用 BS4进行抓取,但由于数据是隐藏的,我无法具体到只能获取所有时间点。我发现这是成功的,因为我能够获得一个包含我需要的所有数据和日期作为标题的表格。我对这个解决方案的问题是 1) 填充 csv 的无用数据 2) 表是垂直的而不是水平的使用 CSS 选择器抓取数据,但我放弃了这个想法,因为有时页面无法加载并且数据没有被抓取。马上发现有一个json文件包含数据Json 抓取似乎是最好的选择,但在创建可以用来制作图表的 csv 文件时遇到困难。这就是让我陷入困境的原因:将数据存储在一个看起来像这样的表中,其中灰色区域是点,DATE1 是数据被抓取的时刻:我不想过多地操作 csv 文件中的数据。如果表格看起来像我上面的图片,那么之后制作图表会更容易,但我遇到了麻烦。我做得最好的就是创建一个看起来像这样的表格,并且是垂直的而不是水平的。name,points,dateDennis,52570,10-23-2020Dinh,40930,10-23-2020name,points,dateDennis,52570,10-23-2020Dinh,40930,10-23-2020name,points,dateDennis,52570,10-23-2020Dinh,40930,10-23-2020感谢您的帮助。这是代码import pandas as pdimport timetimestr = time.strftime("%Y-%m-%d %H:%M")url_all_time = 'https://community.koodomobile.com/widget/pointsLeaderboard?period=allTime&maxResults=20&excludeRoles='data = pd.read_json(url_all_time)table = pd.DataFrame.from_records(data, index=['name'], columns=['points','name'])table['date'] = pd.Timestamp.today().strftime('%m-%d-%Y')table.to_csv('products.csv', index=True, encoding='utf-8')如果我想要的不可能,我可能只是为每个成员单独抓取,为每个成员制作一个 CSV 文件,并制作一个引用这些不同文件的图表。
2 回答
一只萌萌小番薯
TA贡献1795条经验 获得超7个赞
所以,我稍微思考了一下你的问题,这就是我的想法。
基本上,数据存储的最佳选择是轻量级数据库,如评论中所建议的。然而,通过一些计划、一些跳跃和一些黑客代码,你可以通过一个简单的(某种)JSON最终得到一个.csv如下所示的文件:
注意:这些值是相同的,因为我不想等待一两天排行榜才真正更新。
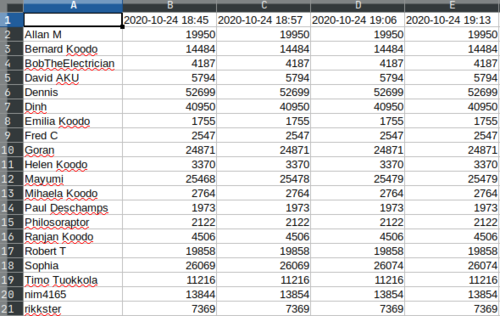
我所做的就是重新排列从 API 请求返回的数据,并构建一个如下所示的结构:
"BobTheElectrician": {
"id": 7160010,
"rank": 14,
"score_data": {
"2020-10-24 18:45": 4187,
"2020-10-24 18:57": 4187,
"2020-10-24 19:06": 4187,
"2020-10-24 19:13": 4187
}
每个球员都是你的主要关键,除其他外,都有其scores_data价值。这反过来又为您运行脚本的每一天dict保留价值。points
现在,诀窍是让它JSON看起来像.csv你想要的。问题是——如何?
好吧,既然您打算更新所有玩家的数据(我只是假设),他们都应该具有相同数量的
score_data.的键
score_data是您的时间戳。抓住任何玩家的score_data钥匙,你就会得到日期标题,对吗?话虽如此,您可以以
.csv相同的方式构建行:从 中获取玩家的姓名及其所有分值score_data。这应该会给你一个列表的列表,对吧?正确的。
然后,当您拥有所有这些后,您只需将其转储到一个.csv文件中即可!
把它们放在一起:
import csv
import json
import os
import random
import time
from urllib.parse import urlencode
import requests
API_URL = "https://community.koodomobile.com/widget/pointsLeaderboard?"
LEADERBOARD_FILE = "leaderboard_data.json"
def get_leaderboard(period: str = "allTime", max_results: int = 20) -> list:
payload = {"period": period, "maxResults": max_results}
return requests.get(f"{API_URL}{urlencode(payload)}").json()
def dump_leaderboard_data(leaderboard_data: dict) -> None:
with open("leaderboard_data.json", "w") as jf:
json.dump(leaderboard_data, jf, indent=4, sort_keys=True)
def read_leaderboard_data(data_file: str) -> dict:
with open(data_file) as f:
return json.load(f)
def parse_leaderboard(leaderboard: list) -> dict:
return {
item["name"]: {
"id": item["id"],
"score_data": {
time.strftime("%Y-%m-%d %H:%M"): item["points"],
},
"rank": item["leaderboardPosition"],
} for item in leaderboard
}
def update_leaderboard_data(target: dict, new_data: dict) -> dict:
for player, stats in new_data.items():
target[player]["rank"] = stats["rank"]
target[player]["score_data"].update(stats["score_data"])
return target
def leaderboard_to_csv(leaderboard: dict) -> None:
data_rows = [
[player] + list(stats["score_data"].values())
for player, stats in leaderboard.items()
]
random_player = random.choice(list(leaderboard.keys()))
dates = list(leaderboard[random_player]["score_data"])
with open("the_data.csv", "w") as output:
w = csv.writer(output)
w.writerow([""] + dates)
w.writerows(data_rows)
def script_runner():
if os.path.isfile(LEADERBOARD_FILE):
fresh_data = update_leaderboard_data(
target=read_leaderboard_data(LEADERBOARD_FILE),
new_data=parse_leaderboard(get_leaderboard()),
)
leaderboard_to_csv(fresh_data)
dump_leaderboard_data(fresh_data)
else:
dump_leaderboard_data(parse_leaderboard(get_leaderboard()))
if __name__ == "__main__":
script_runner()
该脚本还会检查您是否有一个JSON冒充正确数据库的文件。如果没有,它将写入排行榜数据。下次运行该脚本时,它将更新JSON并生成一个新.csv文件。
希望这个答案能引导您走向正确的方向。
DIEA
TA贡献1820条经验 获得超3个赞
嘿,既然您将其加载到 panda 框架中,那么操作就相当简单了。我先运行你的代码
import pandas as pd
import time
timestr = time.strftime("%Y-%m-%d %H:%M")
url_all_time = 'https://community.koodomobile.com/widget/pointsLeaderboard?period=allTime&maxResults=20&excludeRoles='
data = pd.read_json(url_all_time)
table = pd.DataFrame.from_records(data, index=['name'], columns=['points','name'])
table['date'] = pd.Timestamp.today().strftime('%m-%d-%Y')
然后我添加了几行代码来根据您的需要修改 panda 框架表。
idxs = table['date'].index
for i,val in enumerate(idxs):
table.at[ val , table['date'][i] ] = table['points'][i]
table = table.drop([ 'date', 'points' ], axis = 1)
在上面的代码片段中,我使用 pandas 框架通过索引分配值的能力。因此,首先我获取日期列的索引值,然后遍历每个索引值以添加所需日期的列(日期列中的值),并根据我们之前提取的索引获取相应的点
这给了我以下输出:
name 10-24-2020
Dennis 52570.0
Dinh 40930.0
Sophia 26053.0
Mayumi 25300.0
Goran 24689.0
Robert T 19843.0
Allan M 19768.0
Bernard Koodo 14404.0
nim4165 13629.0
Timo Tuokkola 11216.0
rikkster 7338.0
David AKU 5774.0
Ranjan Koodo 4506.0
BobTheElectrician 4170.0
Helen Koodo 3370.0
Mihaela Koodo 2764.0
Fred C 2542.0
Philosoraptor 2122.0
Paul Deschamps 1973.0
Emilia Koodo 1755.0
然后我可以使用代码中的最后一行将其保存到 csv 中。类似地,您可以提取更多日期的数据并将其格式化以将其添加到同一个熊猫框架中
table.to_csv('products.csv', index=True, encoding='utf-8')
添加回答
举报
0/150
提交
取消