我想使用AIF360计算群体公平性指标。这是一个示例数据集和模型,其中性别是受保护的属性,收入是目标。import pandas as pdfrom sklearn.svm import SVCfrom aif360.sklearn import metricsdf = pd.DataFrame({'gender': [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1], 'experience': [0, 0.1, 0.2, 0.4, 0.5, 0.6, 0, 0.1, 0.2, 0.4, 0.5, 0.6], 'income': [0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1, 1]})clf = SVC(random_state=0).fit(df[['gender', 'experience']], df['income'])y_pred = clf.predict(df[['gender', 'experience']])metrics.statistical_parity_difference(y_true=df['income'], y_pred=y_pred, prot_attr='gender', priv_group=1, pos_label=1)它抛出:---------------------------------------------------------------------------TypeError Traceback (most recent call last)<ipython-input-7-609692e52b2a> in <module> 11 y_pred = clf.predict(X) 12 ---> 13 metrics.statistical_parity_difference(y_true=df['income'], y_pred=y_pred, prot_attr='gender', priv_group=1, pos_label=1)TypeError: statistical_parity_difference() got an unexpected keyword argument 'y_true'类似的错误disparate_impact_ratio。似乎数据需要以不同的方式输入,但我一直无法弄清楚如何输入。
3 回答
慕娘9325324
TA贡献1783条经验 获得超5个赞
这可以通过将数据转换为 aStandardDataset然后调用fair_metrics以下函数来完成:
from aif360.datasets import StandardDataset
from aif360.metrics import BinaryLabelDatasetMetric, ClassificationMetric
dataset = StandardDataset(df,
label_name='income',
favorable_classes=[1],
protected_attribute_names=['gender'],
privileged_classes=[[1]])
def fair_metrics(dataset, y_pred):
dataset_pred = dataset.copy()
dataset_pred.labels = y_pred
attr = dataset_pred.protected_attribute_names[0]
idx = dataset_pred.protected_attribute_names.index(attr)
privileged_groups = [{attr:dataset_pred.privileged_protected_attributes[idx][0]}]
unprivileged_groups = [{attr:dataset_pred.unprivileged_protected_attributes[idx][0]}]
classified_metric = ClassificationMetric(dataset, dataset_pred, unprivileged_groups=unprivileged_groups, privileged_groups=privileged_groups)
metric_pred = BinaryLabelDatasetMetric(dataset_pred, unprivileged_groups=unprivileged_groups, privileged_groups=privileged_groups)
result = {'statistical_parity_difference': metric_pred.statistical_parity_difference(),
'disparate_impact': metric_pred.disparate_impact(),
'equal_opportunity_difference': classified_metric.equal_opportunity_difference()}
return result
fair_metrics(dataset, y_pred)
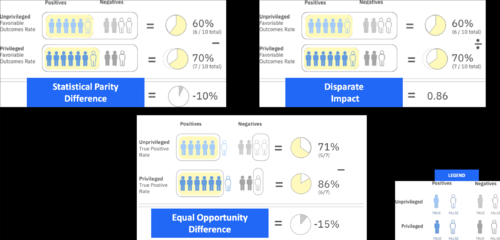
它返回正确的结果(图像参考):
{'statistical_parity_difference': -0.6666666666666667,
'disparate_impact': 0.3333333333333333,
'equal_opportunity_difference': 0.0}
Qyouu
TA贡献1786条经验 获得超11个赞
哆啦的时光机
TA贡献1779条经验 获得超6个赞
我有同样的问题。y_pred_default是数组类型,整个数据集是Dataframe。但是,如果将 y_pred_default 转换为数据帧,您将丢失值的顺序,因此它将向新数据集显示 nan 值。所以我将数据集转换为 numpy 数组,然后与 y_pred_default 数组连接并转换为数据帧。此外,您还必须首先更改列名称,因为现在有数字。通过这样做,你就得到了你想要的。包含 x 值和相应 y 预测值的数据框,用于计算 spd 指标。
添加回答
举报
0/150
提交
取消