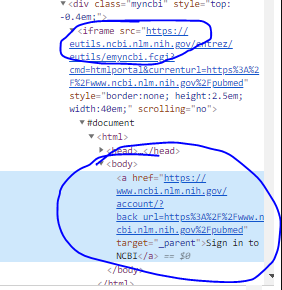
我是硒和网络自动化任务的新手,我正在尝试使用 chromedriver 编写一个应用程序,用于在 PubMed 上自动搜索论文。我的目标是点击 PubMed 主页右上角的“登录”按钮,所以问题是:当我手动打开 PubMed 主页时,html 源中没有 iframes 标签,因此“登录”元素应该可以通过其 xpath 轻松访问"//*[@id="sign_in"]"。当同一页面由 selenium 打开时,我无法通过其 xpath 找到“登录”元素,并且如果尝试检查它,html 源似乎已将其嵌入到标签中<iframe>,因此无法再找到它,除非一个driver._switch_to.frame方法被执行。但是如果我打开html源代码并Ctrl+U搜索<iframe>element,仍然没有它们。这是“登录”元素检查捕获:["Sign in" inspection][1]我已经通过以下方式解决了这个问题:bot = PubMedBot()bot.driver.get('https://www.ncbi.nlm.nih.gov/pubmed')sleep(2)frames = bot.driver.find_elements_by_tag_name('iframe')bot.driver._switch_to.frame(frames[0])btn = bot.driver.find_element_by_xpath('/html/body/a')btn.click()但我想了解的是为什么检查代码与 html 源代码不同,这个<iframe>元素是否真的不知从何而来,如果是的话为什么。
1 回答
守着一只汪
TA贡献1872条经验 获得超4个赞
您因同步而遇到问题。请找到以下解决方案来解决您的问题:
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r"path ofchromedriver.exe")
driver.maximize_window()
wait = WebDriverWait(driver, 10)
driver.get("https://www.ncbi.nlm.nih.gov/pubmed")
iframe = wait.until(EC.presence_of_element_located((By.TAG_NAME, "iframe")))
driver.switch_to.frame(iframe)
wait.until(EC.element_to_be_clickable((By.XPATH, "//a[contains(text(), 'Sign in to NCBI')]"))).click()
输出:
检查元素:
- 1 回答
- 0 关注
- 254 浏览
添加回答
举报
0/150
提交
取消