在 Azure Databricks 笔记本中,我尝试使用以下命令对 Blob 存储中的某些 csv 执行转换:*import os import glob import pandas as pd os.chdir(r'wasbs://dalefactorystorage.blob.core.windows.net/dale') allFiles = glob.glob("*.csv") # match your csvs for file in allFiles: df = pd.read_csv(file) df = df.iloc[4:,] # read from row 4 onwards. df.to_csv(file) print(f"{file} has removed rows 0-3")*不幸的是我收到以下错误:*FileNotFoundError: [Errno 2] 没有这样的文件或目录: 'wasbs://dalefactorystorage.blob.core.windows.net/dale'我错过了什么吗?(我对此完全陌生)。
2 回答
DIEA
TA贡献1820条经验 获得超3个赞
如果您想使用包pandas从 Azure blob 读取 CSV 文件,对其进行处理并将此 CSV 文件写入 Azure Databricks 中的 Azure blob,我建议您将 Azure blob 存储挂载为 Databricks 文件系统,然后执行此操作。欲了解更多详情,请参阅此处。
例如
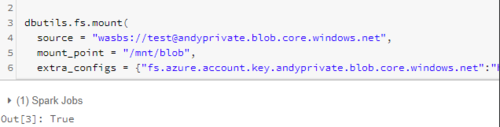
装载 Azure 斑点
dbutils.fs.mount(
source = "wasbs://<container-name>@<storage-account-name>.blob.core.windows.net",
mount_point = "/mnt/<mount-name>",
extra_configs = {"fs.azure.account.key.<storage-account-name>.blob.core.windows.net":"<account access key>"})
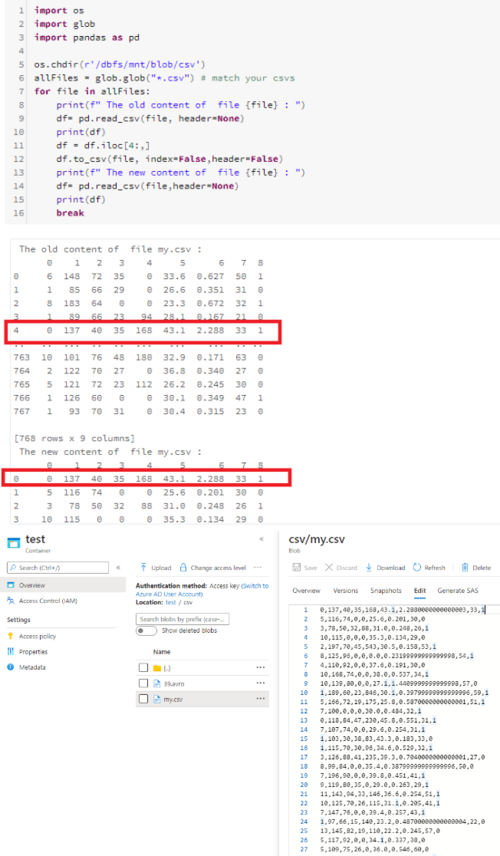
处理 csv
import os
import glob
import pandas as pd
os.chdir(r'/dbfs/mnt/<mount-name>/<>')
allFiles = glob.glob("*.csv") # match your csvs
for file in allFiles:
print(f" The old content of file {file} : ")
df= pd.read_csv(file, header=None)
print(df)
df = df.iloc[4:,]
df.to_csv(file, index=False,header=False)
print(f" The new content of file {file} : ")
df= pd.read_csv(file,header=None)
print(df)
break
慕雪6442864
TA贡献1812条经验 获得超5个赞
A,替代方法是将 dbfs 文件挂载为 Spark 数据帧,然后将其从 Sparkdf 转换为 pandas df:
# mount blob storage
spark.conf.set("fs.azure.account.key.storageaccountname.blob.core.windows.net",
"storageaccesskey")
dfspark = spark.read.csv("wasbs://containername@storageaccountname.blob.core.windows.net
/filename.csv", header="true")
# convert from sparkdf to pandasdf
df = dfspark.toPandas()
添加回答
举报
0/150
提交
取消