UPDATE2:我实际上有 2000 次抽奖,而不是 3 次。更新:我的 df A 列是错误的。我修好了它。我有下面的一个非常大的版本df。data = {'A':[11111, 11111, 33333,11111], 'B':[101, 101, 102, 101],'C':[1,2,3,4], 'draw0':[5, 6, 2, 1], 'draw1':[4,3,2,1], 'draw2':[2,3,4,6]}df = pd.DataFrame(data) A B C draw0 draw1 draw20 11111 101 1 5 4 21 11111 101 2 6 3 32 33333 102 3 2 2 43 11111 101 4 1 1 6我试图找出每次抽奖中哪些抽奖列获胜。以下是我当前的尝试,虽然速度缓慢,但有效。我觉得应该有一种方法可以应用或使它更快。draw_cols = [col for col in df if col.startswith('draw')]for col in draw_cols: max_idx = df.groupby(['A', 'B'])[col].idxmax().values df.loc[max_idx, col] = 1 df.loc[~df.index.isin(max_idx), col] = 0期望的输出: A B C draw0 draw1 draw20 11111 101 1 0 1 01 11111 101 2 1 0 02 33333 102 3 1 1 13 11111 101 4 0 0 1我生成 2000 列,如下所示:def simulateDraw(df, n=2000): #simulate n drawings from the alpha and beta values and create columns return pd.concat([df, df.apply(lambda row: pd.Series(np.random.beta(row.C, row.C, size=n)), axis = 1).add_prefix('draw')], axis = 1)
3 回答
白猪掌柜的
TA贡献1893条经验 获得超10个赞
# groupby and transform the idxmax
max_idx = df.groupby(['A', 'B'])[df.columns[3:]].transform('idxmax')
# create a new column that is just your index
# this is done just in case your real data does not have a range index
max_idx['index'] = max_idx.index.values
# where the max_idx is in the index to return bool values and then update the original df
df.update(max_idx.isin(max_idx['index']).astype(int))
A B C draw0 draw1 draw2
0 11111 101 1 0 1 0
1 11111 101 2 1 0 0
2 33333 102 3 1 1 1
3 11111 101 4 0 0 1
绝地无双
TA贡献1946条经验 获得超4个赞
检查每个组的哪一draw列等于该列的最大值
df.update(df.groupby(['A','B'])[['draw0','draw1','draw2']].apply(lambda x: x.eq(x.max(0))).astype('int'))
df
出去:
A B C draw0 draw1 draw2
0 11111 101 1 0 1 0
1 11111 101 2 1 0 0
2 33333 102 3 1 1 1
3 11111 101 4 0 0 1
微基准测试
结果simulateDraw(df, n=4)
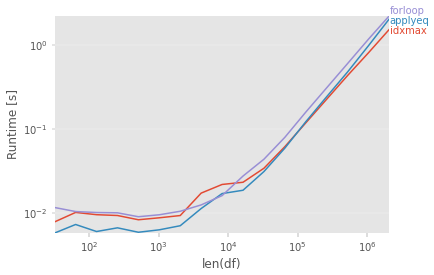
结果simulateDraw(df, n=50)(更多的行或列超出了我的耐心和 Colab 实例上的 RAM)
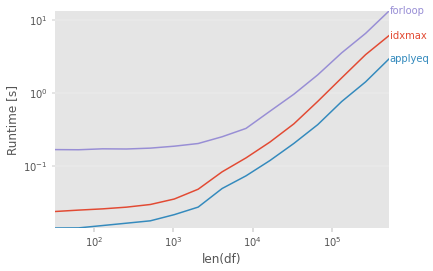
用于基准测试的代码
import pandas as pd
import numpy as np
import perfplot
def simulateDraw(df, n=2000):
return pd.concat([df,
df.apply(lambda row: pd.Series(np.random.beta(row.C, row.C, size=n)), axis = 1).add_prefix('draw')],
axis = 1)
def makedata(n=1):
data = pd.DataFrame({'A':[11111, 11111, 33333,11111] * n, 'B':[101, 101, 102, 101] * n,'C':[1,2,3,4] * n})
data = simulateDraw(data)
return data
def forloop(df):
draw_cols = [col for col in df if col.startswith('draw')]
for col in draw_cols:
max_idx = df.groupby(['A', 'B'])[col].idxmax().values
df.loc[max_idx, col] = 1
df.loc[~df.index.isin(max_idx), col] = 0
return df
def applyeq(df):
draw_cols = [col for col in df if col.startswith('draw')]
df.update(df.groupby(['A','B'])[draw_cols].apply(lambda x: x.eq(x.max(0))).astype('int'))
return df
def idxmax(df):
draw_cols = [col for col in df if col.startswith('draw')]
max_idx = df.groupby(['A', 'B'])[draw_cols].transform('idxmax')
max_idx['index'] = max_idx.index.values
df.update(max_idx.isin(max_idx['index']).astype(int))
return df
perfplot.show(
setup=makedata,
kernels=[idxmax,applyeq,forloop],
n_range=[2**k for k in range(5,22)],
xlabel='len(df)'
)
守候你守候我
TA贡献1802条经验 获得超10个赞
这种嵌套列表理解不需要 groupby,但可以更快地更新值(它取代了对apply lambda应用于每个元素的 ' '的需要np.where)。如果你的规模很大的话,它可能会更有效dataframe(尽管我没有运行任何性能指标!)
out = pd.concat(
[
pd.concat(
[
pd.DataFrame(
np.where(
df.loc[df.B.isin([i]),['draw0','draw1','draw2']]==df.loc[df.B.isin([i]),['draw0','draw1','draw2']].max().to_numpy()[None,:],1,0
)
).reset_index(drop=True),\
df.loc[df.B.isin([i]),['A','B','C']].reset_index(drop=True)
], axis=1, sort=False, ignore_index=True
) for i in df.B.unique()
], axis=0, sort=False, ignore_index=True
)
out.rename(columns = {0:'draw0',1:'draw1',2:'draw2',3:'A',4:'B',5:'C'}, inplace=True)
添加回答
举报
0/150
提交
取消