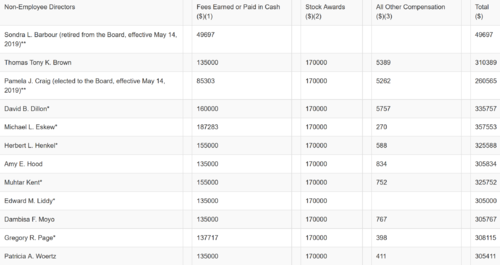
我正在尝试从以下URL中提取 html 表。例如,第 44 页的 2019 年董事薪酬表。我相信该表没有特定的 id,例如“薪酬表”等。要提取该表,我只能想到匹配的列名称或关键字,例如“股票奖励”或“所有其他补偿”,然后抓取关联的表。有没有一种简单的方法可以根据列名提取这些表?或者也许有更简单的方法?谢谢!我在抓取 HTML 表方面相对较新..我的代码如下from bs4 import BeautifulSoupimport requestsurl = 'https://www.sec.gov/Archives/edgar/data/66740/000120677420000907/mmm3661701-def14a.htm'r = requests.get(url) soup = BeautifulSoup(r.text, 'html.parser')rows = soup.find_all('tr')
1 回答
www说
TA贡献1775条经验 获得超8个赞
当然,您可以根据文档pandas read_html使用函数 usingmatch和 来做到这一点。attrs
import pandas as pd
df = pd.read_html(
"https://www.sec.gov/Archives/edgar/data/66740/000120677420000907/mmm3661701-def14a.htm", attrs={'style': 'border-collapse: collapse; width: 100%; font: 9pt Arial, Helvetica, Sans-Serif'}, match="Non-Employee Directors")
print(df)
df[0].to_csv("data.csv", index=False, header=False)
输出:
- 1 回答
- 0 关注
- 221 浏览
添加回答
举报
0/150
提交
取消