我参考了以下帖子,它非常有帮助,但我需要更进一步。 Python - 从列表中搜索数据框中的字符串我不仅想在数据框中搜索单词列表,还想跟踪是否找到多个单词及其频率。因此,使用上面帖子中的示例:如果这是我的搜索列表search_list = ['STEEL','IRON','GOLD','SILVER']这是我正在搜索的数据框 a b 0 123 'Blah Blah Steel'1 456 'Blah Blah Blah Steel Gold'2 789 'Blah Blah Gold'3 790 'Blah Blah blah'我希望我的输出是 a b c d0 123 'Blah Blah Steel' 'STEEL' 11 789 'Blah Blah Steel Gold' 'STEEL','GOLD' 22 789 'Blah Blah Gold' 'GOLD' 13 790 'Blah Blah blah'我如何扩展上述帖子中的出色解决方案以获得所需的输出?我目前正在利用投票最高的答案作为起点。我更关心能够从列表中标记多个单词。我还没有找到任何方法来做到这一点。如果在此步骤中无法执行此操作,我可以将字符串计数函数应用于数据框以创建频率列。如果有一种方法可以一步完成这一切,那也很好。
2 回答
翻阅古今
TA贡献1780条经验 获得超5个赞
您可以使用re.findall()而不是 extract() 来执行您需要的操作。
import re
search_list = ['STEEL','IRON','GOLD','SILVER']
df['c'] = df.b.str.findall('({0})'.format('|'.join(search_list)), flags=re.IGNORECASE)
df['d'] = df['c'].str.len()
这个输出看起来像这样:
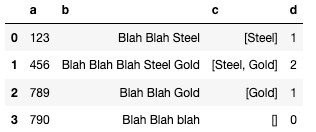
UYOU
TA贡献1878条经验 获得超4个赞
#turn column b into a list of uppercases
df.b=df.b.str.upper().str.split('\s')
#Because you have two lists, use the apply function to turn them into sets
#..and leverage the rich membership functions encased in sets.
# Using intersection, you will find items in each list.
#Then use list.str.len() to count.
df=df.assign(c=df.b.apply(lambda x:[*{*x}&{*search_list}])\
.str.join(','),d=df.b.apply(lambda \
x:[*{*x}&{*search_list}]).str.len())
b c d
0 [BLAH, BLAH, STEEL] STEEL 1
1 [BLAH, BLAH, STEEL, GOLD] GOLD,STEEL 2
2 [BLAH, BLAH, GOLD] GOLD 1
3 [BLAH, BLAH, BLAH] 0
添加回答
举报
0/150
提交
取消