我对 Python 中的 Beautiful Soup 非常熟悉,我一直用来抓取实时网站。现在我正在抓取本地 HTML 文件(链接,如果您想测试代码),唯一的问题是重音字符没有以正确的方式表示(在抓取实时网站时,我从未发生过这种情况)。这是代码的简化版本import requests, urllib.request, time, unicodedata, csvfrom bs4 import BeautifulSoupsoup = BeautifulSoup(open('AH.html'), "html.parser")tables = soup.find_all('table')titles = tables[0].find_all('tr')print(titles[55].text)打印以下输出2:22 - Il Destino È Già Scritto (2017 ITA/ENG) [1080p] [BLUWORLD]而正确的输出应该是2:22 - Il Destino È Già Scritto (2017 ITA/ENG) [1080p] [BLUWORLD]我寻找解决方案,阅读了许多问题/答案并找到了这个答案,我通过以下方式实现了它import requests, urllib.request, time, unicodedata, csvfrom bs4 import BeautifulSoupimport codecsresponse = open('AH.html')content = response.read()html = codecs.decode(content, 'utf-8')soup = BeautifulSoup(html, "html.parser")但是,它运行时出现以下错误Traceback (most recent call last): File "C:\Users\user\AppData\Local\Programs\Python\Python37-32\lib\encodings\utf_8.py", line 16, in decode return codecs.utf_8_decode(input, errors, True)TypeError: a bytes-like object is required, not 'str'The above exception was the direct cause of the following exception:Traceback (most recent call last): File "C:\Users\user\Desktop\score.py", line 8, in <module> html = codecs.decode(content, 'utf-8')TypeError: decoding with 'utf-8' codec failed (TypeError: a bytes-like object is required, not 'str')我想解决这个问题很容易,但是怎么办呢?
2 回答
慕姐8265434
TA贡献1813条经验 获得超2个赞
使用open('AH.html')使用默认编码对文件进行解码,该默认编码可能不是文件的编码。 BeautifulSoup理解 HTML 标头,特别是以下内容表明该文件是 UTF-8 编码的:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
以二进制模式打开文件并BeautifulSoup计算出来:
with open("AH.html","rb") as f:
soup = BeautifulSoup(f, 'html.parser')有时,网站设置的编码不正确。在这种情况下,如果您知道编码应该是什么,您可以自己指定编码。
with open("AH.html",encoding='utf8') as f:
soup = BeautifulSoup(f, 'html.parser')
梦里花落0921
TA贡献1772条经验 获得超6个赞
from bs4 import BeautifulSoup
with open("AH.html") as f:
soup = BeautifulSoup(f, 'html.parser')
tb = soup.find("table")
for item in tb.find_all("tr")[55]:
print(item.text)
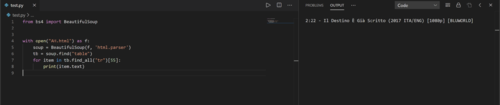
我不得不说,您的第一个代码实际上很好并且应该可以工作。
关于第二个代码,您正在尝试decode str哪个是错误的。因为decode函数是为byte object.
我相信您正在使用Windows它的默认编码不是cp1252的地方UTF-8。
您能否运行以下代码:
import sys print(sys.getdefaultencoding()) print(sys.stdin.encoding) print(sys.stdout.encoding) print(sys.stderr.encoding)
并检查你的输出是否是UTF-8或cp1252。
请注意,如果您使用
VSCodewithCode-Runner,请在终端中运行您的代码py code.py
解决方案(来自聊天)
(1) 如果您使用的是 Windows 10
打开控制面板并通过小图标更改视图
单击区域
单击管理选项卡
单击更改系统区域设置...
勾选“Beta:使用 Unicode UTF-8...”框
单击“确定”并重新启动您的电脑
(2)如果你不是Windows 10或者只是不想改变之前的设置,那么在第一段代码中改为open("AH.html"),open("AH.html", encoding="UTF-8")即写:
from bs4 import BeautifulSoup
with open("AH.html", encoding="UTF-8") as f:
soup = BeautifulSoup(f, 'html.parser')
tb = soup.find("table")
for item in tb.find_all("tr")[55]:
print(item.text)
- 2 回答
- 0 关注
- 280 浏览
添加回答
举报
0/150
提交
取消