我有这个数据:import pandas as pdimport numpy as npindex = pd.MultiIndex.from_tuples(list(zip(*[['one', 'one', 'two', 'two'],['foo', 'bar', 'foo', 'bar']])))df = pd.DataFrame(np.arange(12).reshape((3,4)), columns=index) one two foo bar foo bar0 0 1 2 31 4 5 6 72 8 9 10 11有没有一种方法可以对每个 1 级列上的每个 0 级组列进行简单的矢量化计算(如加法),而不必引用特定的列级别对,例如:df[('one','add')] = df[('one','foo')]+df[('one','bar')]我想得到 one two foo bar add foo bar add0 0 1 1 2 3 51 4 5 9 6 7 132 8 9 17 10 11 21
3 回答
喵喔喔
TA贡献1735条经验 获得超5个赞
我摆弄了一会儿,这是我认为可以解决问题的一句台词。它是完全矢量化的,并且不寻址特定的列名称。它还会将add列放置在正确的位置。
df.stack(0).assign(add=df.stack(0).sum(axis=1)).stack(0).unstack(0).T
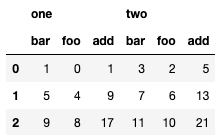
不幸的是,由于 stack / unstack 的特性是对最内层进行入栈 / 出栈,因此需要神秘的.stack(0).unstack(0)操作。看起来这两个操作应该互相抵消,但它们实际上在保持顺序的同时打乱索引级别。
这是同样的事情,分为 3 行,没有赋值语句。
df = df.stack(0)
df['add'] = df.sum(axis=1)
df = df.stack(0).unstack(0).T
慕田峪7331174
TA贡献1828条经验 获得超13个赞
pandas.DataFrame.sum与axis=1和 一起使用level=0:
df2 = df.sum(axis=1, level=0)
print(df2)
输出:
one two
0 1 5
1 9 13
2 17 21
然后您可以将新的列名称添加到pandas.concat:
df2.columns = [(c, "add") for c in df2]
df2 = pd.concat([df, df2], 1).sort_index(1)
print(df2)
输出:
one two
add bar foo add bar foo
0 1 1 0 5 3 2
1 9 5 4 13 7 6
2 17 9 8 21 11 10
犯罪嫌疑人X
TA贡献2080条经验 获得超4个赞
这里有一个替代解决方案,使用相同的求和解决方案,但没有pd.concat:
df[("one", "add")] = None
df[("two", "add")] = None
df.iloc[:, -2:] = df.sum(axis=1, level=0).to_numpy()
df.sort_index(1)
one two
add bar foo add bar foo
0 1.0 1 0 5.0 3 2
1 9.0 5 4 13.0 7 6
2 17.0 9 8 21.0 11 10
添加回答
举报
0/150
提交
取消