我是熊猫和 matplotlib 的新手。我有一个 csv 文件,其中包含从 2012 年到 2018 年的年份。对于一年中的每个月,我都有雨数据。我想通过直方图分析一年中哪个月份降雨量最大。这是我的数据集。year month Temp Rain2012 1 10 1002012 2 20 2002012 3 30 300.. .. .. ..2012 12 40 4002013 1 50 3002013 2 60 200.. .. .. ..2018 12 70 400我无法用直方图绘制,我尝试用条形图绘制但没有得到想要的结果。这是我尝试过的:import pandas as pdimport numpy as npyimport matplotlib.pyplot as pltdf2=pd.read_csv('Monthly.csv')df2.groupby(['year','month'])['Rain'].count().plot(kind="bar",figsize=(20,10))这是我得到的输出:请给我建议一种绘制直方图的方法,以分析按年份分组的月份中发生的最大降雨量。
3 回答
米琪卡哇伊
TA贡献1998条经验 获得超6个赞
可能您不想看到count每个组,但是
df2.groupby(['year','month'])['Rain'].first().plot(kind="bar",figsize=(20,10))
或者可能
df2.groupby(['month'])['Rain'].sum().plot(kind="bar",figsize=(20,10))
函数式编程
TA贡献1807条经验 获得超9个赞
您已接近解决方案,我会写:使用 max() 而不是 count()
df2.groupby(['year','month'])['Rain'].max().plot(kind="bar",figsize=(20,10))
喵喵时光机
TA贡献1846条经验 获得超7个赞
第一个 groubby 年和月,就像你已经做的那样,但只保持最大降雨量。
series_df2 = df2.groupby(['year','month'], sort=False)['Rain'].max()
然后拆开系列,转置它并绘制它。
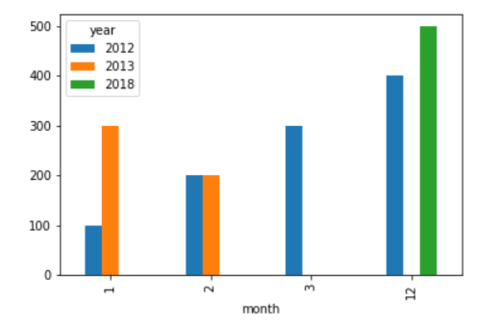
series_df2.unstack().T.plot(kind='bar', subplots=False, layout=(2,2))
这将为您的示例数据提供如下所示的输出:
添加回答
举报
0/150
提交
取消