项目瓶颈一般是数据库,因为机器瓶颈可以用负载均衡器加很多机器解决,数据库读取的瓶颈可以用多个从库来解决,可是并发写入如何提高呢?特别是那种需要马上得到插入结果的,不能用消息队列解决的如何做呢?
1 回答
皈依舞
TA贡献1851条经验 获得超3个赞
个人一些看法:(什么语言都差不多的,我这边是Java的)
省略前头的部分内容,毕竟是比较简单的演化过程
我们将session做成一个session服务器,browser1通过负载均衡请求服务器,服务器将session信息存储到session服务器中,当想要获取时就反向进行。(缺点:目前session Server是单点的,如何解决单点,保证可用性)
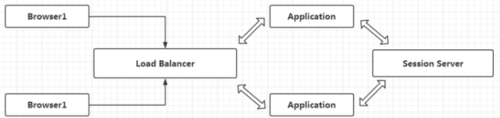
我们可以将Session Server也做成集群,其适合用于Session数量与web服务数量大的情况下,更改架构后,也要修改应用存储session的业务逻辑。
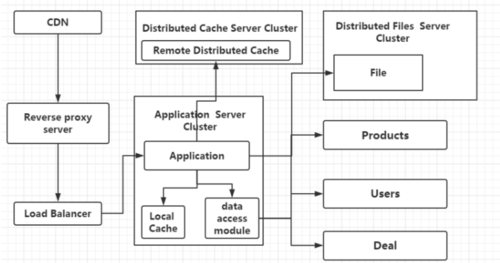
接下来我们再看看数据库,读写都要经过数据库,当用户量达到一定量时,数据库又将成为一个瓶颈,则我们将如何解决?我们可以使用数据库的读写分离,主从库,并通过统一的数据访问模型进行访问,将所有读操作引入到Slave服务器,将写操作引入到主库当中,由于数据库读写分离,所以应用程序也要有相应的变化,使用数据访问模块让应用程序开发人员不用理会读写分离的存在,这样多数据源读写代码对我们的业务就没有了侵入(代码层的演变,如何支持多数据源、如何封装对业务没有侵入、如何使用现用的ORM框架实现数据读写分离、是否更换ORM、其优缺点?)
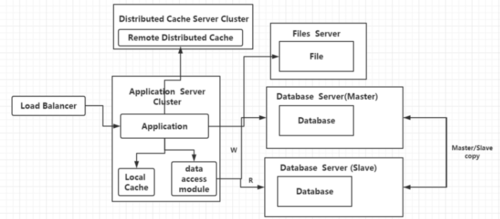
当我们访问过大,I/O过大,我们数据的读写分离又将遇到这几个问题,主从库复制时是否延迟(分机房部署、跨机房传输),应用对于数据源的路由问题,接着我们为了提高服务器,增加了CND和反向代理服务器,使用CDN可以解决不同地方访问速度问题、反向代理可以在机房中缓存用户的资源。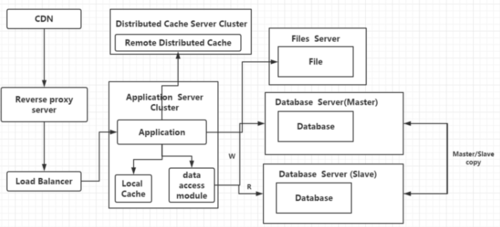
这时文件服务器又出现了瓶颈,我们将文件服务器改为分布式文件服务器集群,我们要考虑到:如何不影响线上的业务访问,是否需要业务部门帮忙清理数据,是否需要备份服务器,是否需要重新做域名解析。
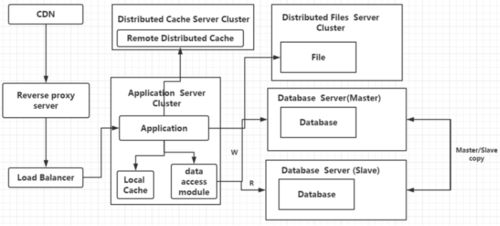
这时我们的数据库又出现了新的瓶颈,我们选择专库专用的方式,进行数据库的垂直拆分,可以解决写数据、并发、量大的问题,分库后又将带来一些新的问题:跨业务的事务(分布式事务)
当某个数据的访问量、数据量、日志等过大达到瓶颈时,这时我们就要进行数据库的水平拆分,我们将User拆分成Users1和Users2,水平拆分即将同一个数据表的数据拆分到两个数据库当中,这时我们就解决了单数据库的瓶颈。
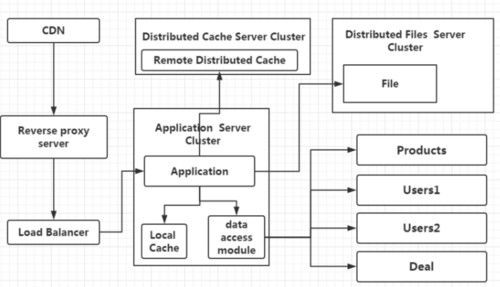
水平拆分后,SQL路由出现一些问题,假设我们想知道某个用户是存在Users1还是Users2中,且由于分库,主键的策略也将有所不同,同时也将面临一个分页的问题(后台管理系统在进行展示时还要考虑分页的问题),当完成后,我们又发现应用服务器的搜索量上升,这时我们将应用服务器的搜索功能提取出来做成搜索引擎,同时部分场景使用NoSQL提高性能,
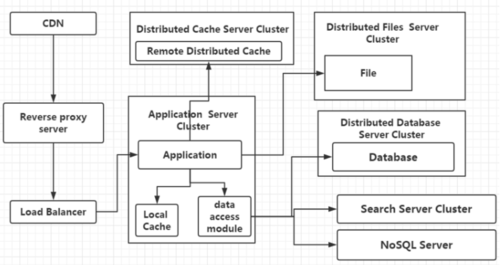
当然以上架构还存在部分问题,如负载均衡服务器是单点,因此也可以将负载均衡服务器做成集群,进行主从的热备,同时做一个自动切换的解决方案。
过程中:安全性、数据分析、监控、反作弊........
继续发展:SOA架构、服务化、消息队列、任务调度、多机房........
- 1 回答
- 0 关注
- 1133 浏览
添加回答
举报
0/150
提交
取消