有一个样本,a列是数字,b列是该数字出现的次数,样本很大,要求这个样本的标准差和正态分布图,请问用python应该怎样处理?查了很多,还是不太懂...A B100 2200 3300 4
1 回答
幕布斯7119047
TA贡献1794条经验 获得超8个赞
关于数据
A B 100 2 200 3 300 4 ...
可以看成一个长这样[100,100,200,200,200,300,300,300,300,...]的list。
标准分布
可以使用numpy的std()来计算标准差,当然自己写公式也可以。比如
In [1]: import numpy as np In [2]: np.std([100,100,200,200,200,300,300,300,300]) Out[2]: 78.56742013183862
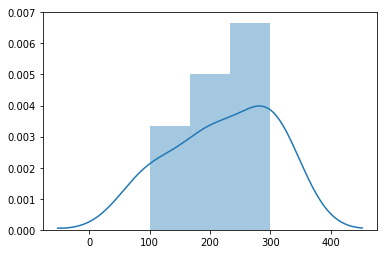
分布图
正态分布图只是正态分布的数据的分布图。是否正态分布取决于你的数据。可以考虑用seaborn来绘制分布图。
import seaborn as sns sns.distplot([100,100,200,200,200,300,300,300,300])
分布图长这样:
大数据量
可以用pandas读取。用一个循环将数据表转为list:
import pandas as pd
df = pd.DataFrame({'A':[100,200,300],'B':[2,3,4]})"""
df 像这样
A B
0 100 2
1 200 3
2 300 4
"""l = []for i, j in zip(df['A'],df['B']):
tmp = [i]*j
l.extend(tmp)
"""
l 像这样
[100, 100, 200, 200, 200, 300, 300, 300, 300]
"""- 1 回答
- 0 关注
- 893 浏览
添加回答
举报
0/150
提交
取消