课程
/后端开发
/Python
/Python数据预处理(一)一抽取多源数据文本信息
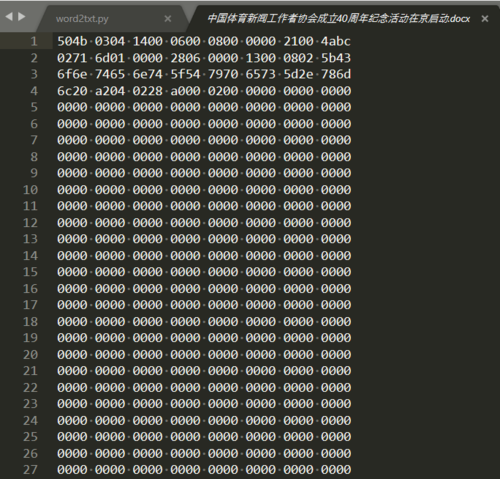
原来的docx文本在sublime中显示数字,转换出来的文本是乱码。应该是编码的问题,但是不知道如何设置。安装了anaconda,所以没有另外导入pywin32.
编译了一下报错。
2019-11-04
源自:Python数据预处理(一)一抽取多源数据文本信息 2-3
正在回答
源文件应该不是正常的文本格式文件
举报
Python数据预处理---人工智能通用技术
2 回答为什么转换中文的word文件是乱码,英文没有问题
1 回答pdf转txt的乱码问题
1 回答pdf转txt后打开乱码
3 回答在pdf转TXT时总是出现'NoneType' object has no attribute 'SaveAs'是什么情况
4 回答在pdf转TXT时总是出现'NoneType' object has no attribute 'SaveAs'是什么情况
购课补贴联系客服咨询优惠详情
慕课网APP您的移动学习伙伴
扫描二维码关注慕课网微信公众号