from urllib.request import urlopen
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
# 获取文档
# fp = open("naacl06-shinyama.pdf", 'rb')
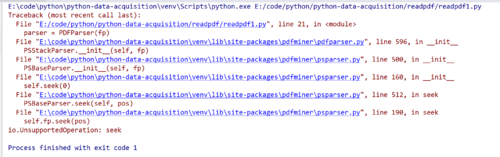
fp = urlopen('https://www.tencent.com/zh-cn/articles/802741466496787.pdf')
# 创建解释器
parser = PDFParser(fp)
# PDF文档对象
doc = PDFDocument()
# 连接解释器和文档对象
parser.set_document(doc)
doc.set_parser(parser)
# 初始化文档
doc.initialize()
# 创建PDF资源管理器
resource = PDFResourceManager()
# 创建一个PDF参数分析器
laparam = LAParams()
# 创建聚合器
device = PDFPageAggregator(resource, laparams=laparam)
# 创建PDF页面解析器
interpreter = PDFPageInterpreter(resource, device)
# 循环遍历列表,每次处理一页的内容
# doc.get_pages() 获取page列表
for page in doc.get_pages():
# 使用页面解释器来读取
interpreter.process_page(page)
# 使用聚合器获得内容
layout = device.get_result()
for out in layout:
if hasattr(out, 'get_text'):
print(out.get_text())