content循环,并没有爬取到第一行的导演主演信息
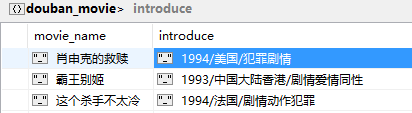

content=i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
#遇到多行数据,进行数据处理
for i_content in content:
content_s="".join(i_content.split()) #通过空格分割
douban_item['introduce']=content_s
content=i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
#遇到多行数据,进行数据处理
for i_content in content:
content_s="".join(i_content.split()) #通过空格分割
douban_item['introduce']=content_s2018-12-07
举报
