课程
/后端开发
/Python
/Python开发简单爬虫
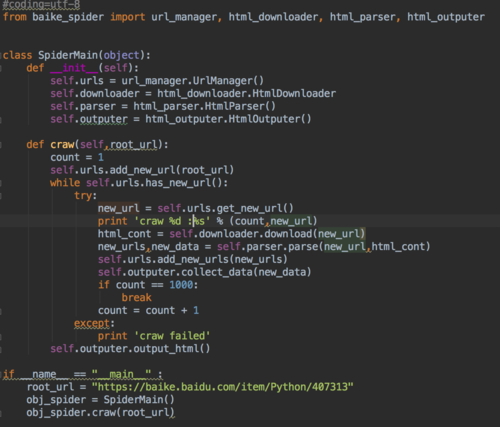
麻烦各位看看~
2018-06-26
源自:Python开发简单爬虫 7-5
正在回答
我也是一样的问题,兄台你解决了吗
一朵阿拉斯加
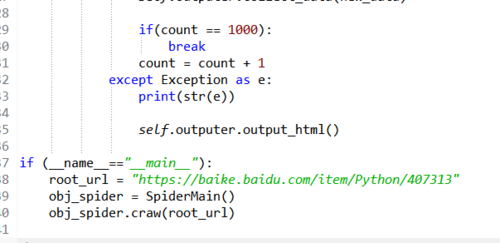
把html_downloader.py中的response = urllib.urlopen(url)改为 response = urllib.request.urlopen(url) 即可,这是由于python2和python3的语法差异,另外python3中urllib2和urllib合并。
python3中parser需要修改成以下的样子
new_full_url = urllib.parse.urljoin(page_url,new_url) 另外加载相应的库的时候注意是这样的from urllib.parse import urlparse
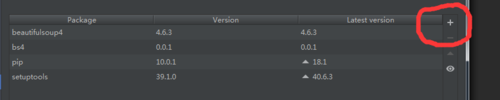
你是在哪个ide里面写的呀 pycharm吗?如果是的话可以file-settings-project Interpreter 然后
搜索parser库然后install
现在解决了?
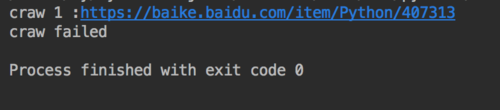
对了,你可以在异常处理那儿改改老师的代码,把异常给输出出来。然后在文件里找哪儿出的毛病。或者贴出来让大家也好解答一点
慕无忌932789
目前图里是没错的。。。可能在其他文件里有错误吧
举报
本教程带您解开python爬虫这门神奇技术的面纱
购课补贴联系客服咨询优惠详情
慕课网APP您的移动学习伙伴
扫描二维码关注慕课网微信公众号