urllib2
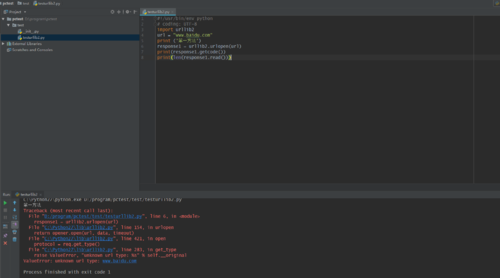 请问这个错在哪里?
请问这个错在哪里?
请问这个错在哪里?
2018-06-13
不知道 你是python第几版 如果是3.4以上的话 要换引用
import urllib.request import http.cookiejar url = "http://www.baidu.com"
也可能是url缺少,我这边运行时没有问题的,python3.6
import urllib.request as ur
import http.cookiejar as hc
url = "http://www.baidu.com"
print("第一种方法")
response1 = ur.urlopen(url)
print(response1.getcode())
print(len(response1.read()))
print("第二种方法")
request = ur.Request(url)
# 将爬虫伪装成浏览器
request.add_header("user-agent", "Mozilla/5.0")
response2 = ur.urlopen(request)
print(response2.getcode())
print(len(response2.read()))
print("第三种方法")
cj = hc.CookieJar()
opener = ur.build_opener(ur.HTTPCookieProcessor(cj))
ur.install_opener(opener)
response3 = ur.urlopen(url)
print(response3.getcode())
print(cj)
print(response3.read())希望对你有帮助。python做第二种编程语言,还是很有帮助的。加油
举报

