课程
/后端开发
/Python
/Python开发简单爬虫
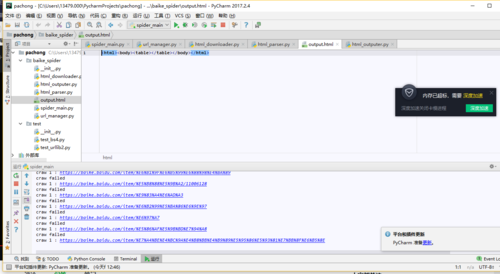
输出的文件没有内容
2018-01-28
源自:Python开发简单爬虫 7-7
正在回答
具体可看https://github.com/lzcdev/BaiDuBaiKeSpider,希望对你有帮助
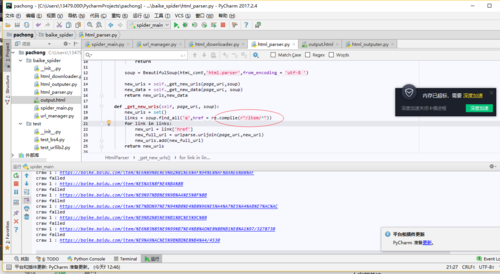
links = soup.find_all('a',href = re.compile(r"/item/%"))
亲测可用。顺带你的图有点看不清,请确保你的href拼写正确。有时会习惯拼成herf。
举报
本教程带您解开python爬虫这门神奇技术的面纱
购课补贴联系客服咨询优惠详情
慕课网APP您的移动学习伙伴
扫描二维码关注慕课网微信公众号