课程
/后端开发
/Python
/Python开发简单爬虫
新手求指导,跪谢各位大神!急急急。。。
2017-03-17
源自:Python开发简单爬虫 7-5
正在回答
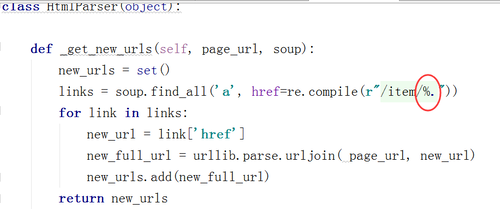
求教,,,我也是html_parser出问题 ,他没说no module 但是就是报错,,还有urlparse也no module 怎么回事
links = soup.find_all('a', href=re.compile(r"/item/\S+"))
/item/%E6%BA%90%E4%BB%A3%E7%A0%81/3969
匹配任意非空字符
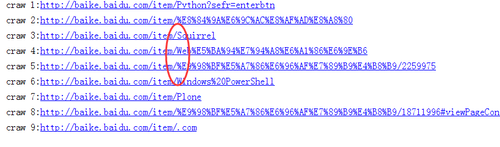
我爬了一下 好像最多只能爬下549条数据。 对于正则表达式,可以参看图片
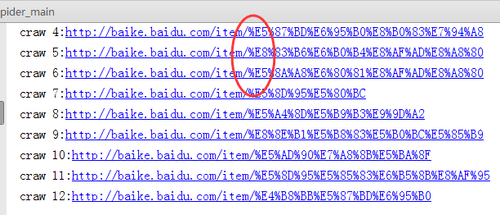
谢谢啦,我的名字命名错误,可是我只能爬出来两条
我发现我进入python百度百科的url和老师不一样,里面的链接url是
这样的,正则需要怎末匹配,查了一下,说是没有转义过来
你看看是不是自己还没创建html_parser
举报
本教程带您解开python爬虫这门神奇技术的面纱
购课补贴联系客服咨询优惠详情
慕课网APP您的移动学习伙伴
扫描二维码关注慕课网微信公众号