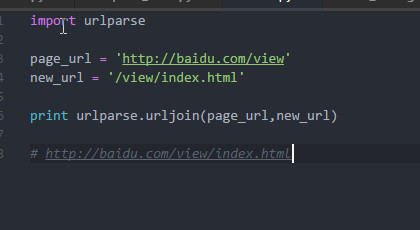
关于page_url的问题,非常重要
尽管对照代码运行成功,但是仍有一个问题,这也是自己编写其他爬虫所遇到的问题
我尝试在html_parser类的的代码做了如下修改:主要是在urljoin前后添加了两个print语句
def _get_new_urls(self, page_url, soup):
new_urls=set()
links=soup.find_all("a",href=re.compile(r"/view/\d+\.htm"))
for link in links:
new_url=link['href']
print new_url
new_full_url=urllib2.urlparse.urljoin(page_url,new_url)
print new_full_url
new_urls.add(new_full_url)
return new_urls
运行结果为:
craw 1 :http://baike.baidu.com/view/21087.htm
/view/10812319.htm
http://baike.baidu.com/view/10812319.htm
/view/2561555.htm
http://baike.baidu.com/view/2561555.htm
......
也就是说page_url为“http://baike.baidu.com”,但是代码全篇并没有定义page_url,这是哪里来的?后面代码在调用函数时,指定
new_urls,new_data=self.parser.parse(new_url,html_cont)
完全不能理解
求大神支教