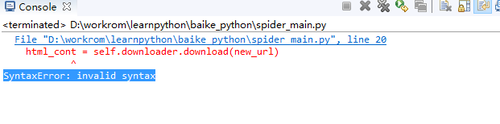
报错---SyntaxError: invalid syntax,实在无奈,找了几天还没找出原因
#环境是eclipse,python3.5
#spider_main
# coding: utf-8
from baike_python import html_downloader, url_manager, html_parser, html_outputer
class SpiderMain(object):
def __init__(self):#构造方法
self.urls = url_manager.UrlManager()#初始化URL管理器
self.downloader = html_downloader.HtmlDownloader()#初始化网页下载器
self.parser = html_parser.HtmlParser()#初始化网页解析器
self.outputer = html_outputer.HtmlOutputer()#初始化输出器
def craw(self, root_url):#开始执行爬虫的方法
count = 1#计数器,计数爬取页面的总数量
count2 = 0#计数器,计数爬取失败的网页个数
self.urls.add_new_url(root_url)#传入网页入口
while self.urls.has_new_url():#对网页内包括的连接网页循环抓取,先判断URL管理器不空
try:#有些页面可能失效了,要有异常处理
new_url = self.urls.get_new_url()#获取URL管理器中的一个URL
print ("craw %d : %s \n"%(count,new_url)#打印当前爬去的页面
html_cont = self.downloader.download(new_url)
new_urls, new_data = self.parser.parse(new_url,html_cont)#把页面解析为新连接和网页数据两部分,其中new_data 中含有当页的链接、title和summary,new_url是当前页面中的所有链接的集合
print (new_data["title"]+"\n", new_data["summary"])
self.urls.add_new_urls(new_urls)#新链接存入URL管理器
self.outputer.collect_data(new_data)#网页数据收集
if count == 10:#控制打印页面的数量
break
count = count+1
except Exception,e:
count2 = count2+1
print('e')
print ("craw failed")
self.outputer.output_html()
print (str(count-count2)+" successful,"," while "+str(count2)+" failed ")
if __name__=="__main__": #主函数
root_url = "http://baike.baidu.com/view/21087.htm" #入口页
obj_spider = SpiderMain()#创建对象
obj_spider.craw(root_url)#启动爬虫#html_downloader
import urllib
class HtmlDownloader(object):
def download(self,url):
if url is None:
return None
#request = urllib2.Request(url)
response = urllib.request.urlopen(url)
if response.getcode() != 200:
return None
return response.read().decode('utf-8')感谢查看,找bug真的烦= =