html_parser部分问题
对于页面中截图部分的文字,
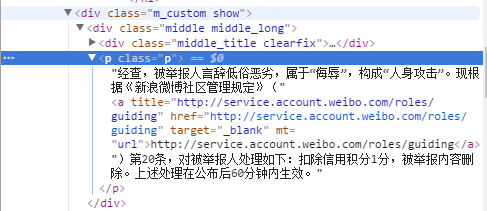
我在html_parser中这样获取,如下图
summary_node = soup.find("div",class_="middle_title clearfix")
res_data['summary'] = summary_node.get_text()
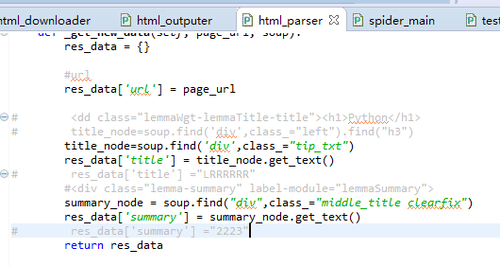
结果显示 :craw failed-- 'NoneType' object has no attribute 'get_text'
这是为什么呢?我用cookie登陆了该网站,但就是爬不了。急求!!!!!!