课程
/后端开发
/Python
/Python开发简单爬虫
我用的是eclipse,Python版本为2.7.12,一直爬取不到信息
2016-08-26
源自:Python开发简单爬虫 8-1
正在回答
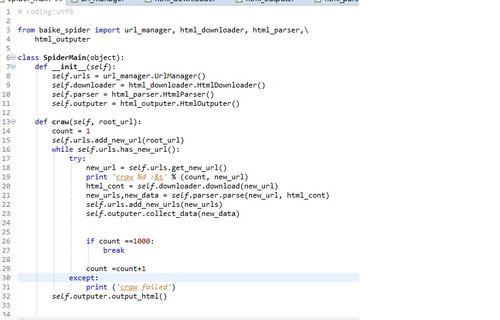
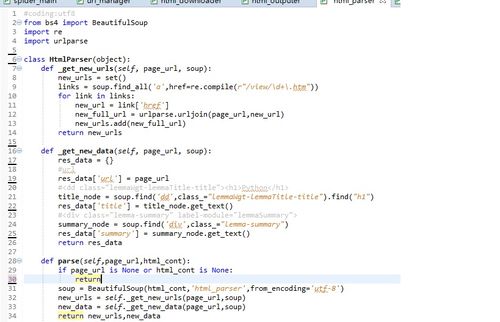
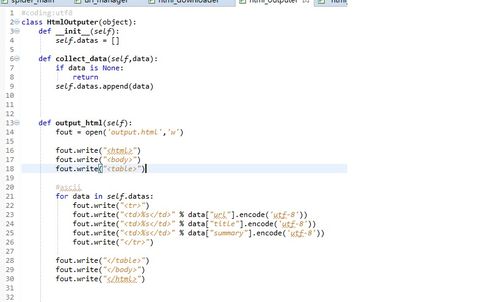
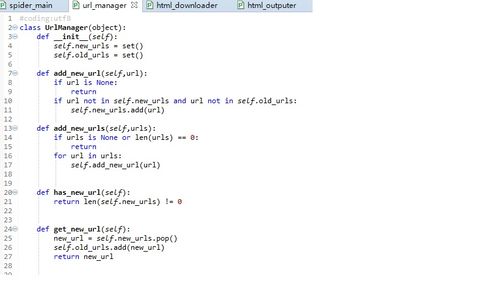
Html_Outputer那个module那里,url不需要转换utf-8
CuiYS
于涵先生 提问者
终于爬出1000个了,谢谢~~
龙宸轩
如果是Python3要改成
from urllib.parse import urlparse
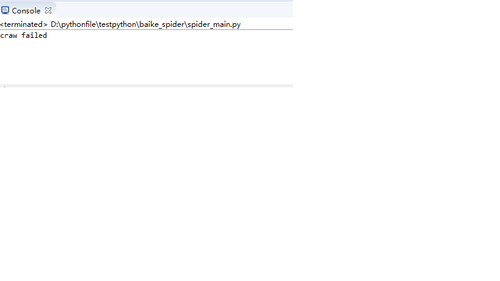
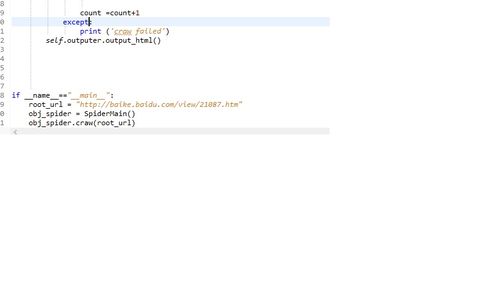
至少能爬root_url。我当时第二行是craw failed 检查以后发现是parser出了问题。 如果这个都没出来,对比一下代码哪里出错了
redain4041661
慕粉3895333
我也是遇到同一样的问题,代码感觉都对了,就是不行
慕粉3956011
你联网了吗?
举报
本教程带您解开python爬虫这门神奇技术的面纱
购课补贴联系客服咨询优惠详情
慕课网APP您的移动学习伙伴
扫描二维码关注慕课网微信公众号