用DOM4J解析XML文件如何解析出其中的注释行
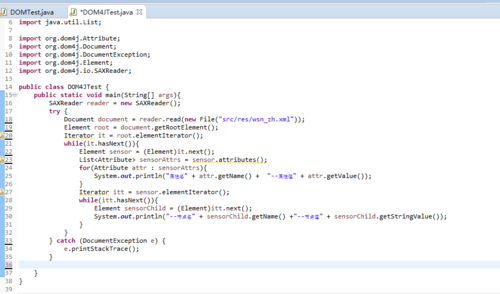

如何修改以上的代码,从而能够解析出注释行??
如何修改以上的代码,从而能够解析出注释行??
2016-08-19
首先,代码是从百度贴的,简单说下,这里如果要解析注释的话,就不能用迭代器Iterator来迭代element了,从代码可以看出,element只是node的接口之一,而注释节点的继承结构里没有element接口,需要使用如下的遍历方式才能得到,原理大概是这样,如有不明白的地方,欢迎追问
Element root= doc.getRootElement();
for (int i = 0, size = root.nodeCount(); i < size; i++)
{
Node node = root.node(i);
if (node instanceof Element) {
System.out.println("This is a Element!");
prinContent(node);
System.out.println();
} else if(node instanceof
org.dom4j.Comment){
System.out.println("This is a Comment!");
prinContent(node);
System.out.println();
}else{
System.out.println("This is a Nothing!");
prinContent(node);
}
}
package com.pwy.xml.dom4j;
import java.io.File;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
public class Test {
public static void main(String[] args) throws Exception {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/com/pwy/xml/dom4j/books.xml"));
Element root= document.getRootElement();
for (int i = 0, size = root.nodeCount(); i < size; i++)
{
Node node = root.node(i);
if (node instanceof Element) {
System.out.println("This is a Element!");
System.out.println();
} else if(node instanceof org.dom4j.Comment){
System.out.println("This is a Comment!");
System.out.println();
}else{
System.out.println("This is a Nothing!");
}
}
}
}
举报
