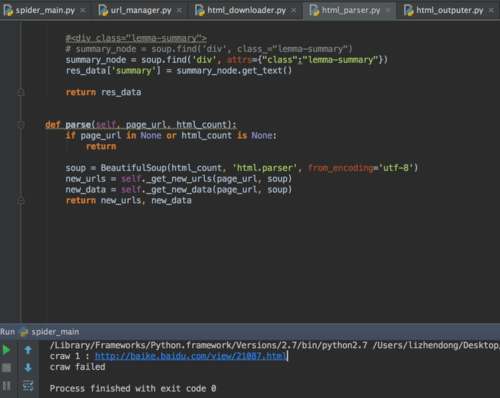
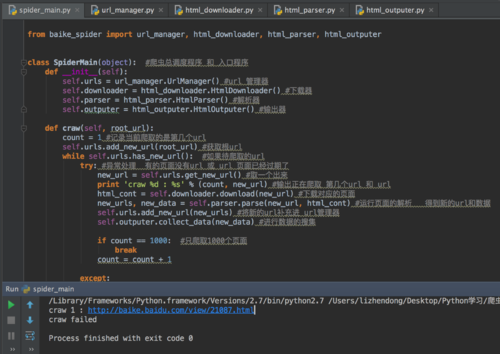
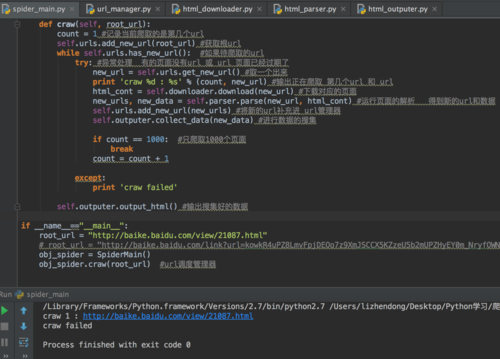
没报错,只输出了第一条记录,然后就craw failed,跳出循环了,怎么回事?
# coding:utf-8
#from baike_spider
import url_manager,html_downloader,html_parser,html_outputer
print html_parser.__name__
class SpiderMain(object):
def __init__(self):
self.urls=url_manager.UrlManager()
self.downloader=html_downloader.HtmlDownloader()
self.parser=html_parser.HtmlParser()
self.outputer=html_outputer.HtmlOutputer()
def craw(self,root_url):
count=1
self.urls.add_new_url(root_url)
while self.urls.has_new_url():
try:
#print self.urls.has_new_url()
new_url=self.urls.get_new_url()
print 'craw %d: %s'%(count,new_url)
html_cont=self.downloader.download(new_url)
print type(html_cont)
new_urls,new_data=self.parser.parse(new_url,html_cont)
print new_urls,new_data
print "test"
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
if count==1000:
break
count=count+1
print "test"
except:
print 'craw failed'
self.outputer.output_html()
if __name__=="__main__":
root_url="http://baike.baidu.com/view/21087.htm"
obj_spider=SpiderMain()
obj_spider.craw(root_url)




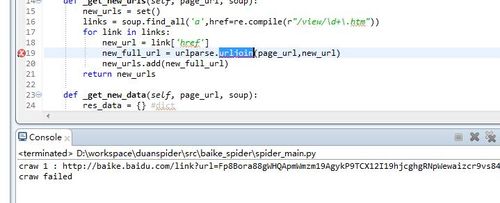 ,为什么老提示我 urljoin 报错啊,我有引入啊
,为什么老提示我 urljoin 报错啊,我有引入啊