用spyder写的但是会出现importerror ,显示是 ImportError: No module named baike_spider
from baike_spider import url_manager,html_downloader,html_parser,html_output class SpiderMain(): def __init__(self): self.urls = url_manager.UrlManager() self.downloader = html_downloader.HtmlDownloader() self.parser = html_parser.HtmlParser() self.outputer = html_output.HtmlOutputer() def craw(self,root_url): count = 1 self.urls.add_new_url(root_url) while self.urls.has_new_url(): try: new_url = self.urls.get_new_url() print 'craw %d: %s'%(count,new_url) html_cont = self.downloader.download(new_url) new_urls,new_data = self.parser.parse(new_url,html_cont) self.urls.add_new_urls(new_urls) self.outputer.collect_data(new_data) if count == 1000: break count = count + 1 except: print 'craw failed' self.outputer.output_html() if __name__=="_main_": root_url = "http://baike.baidu.com/view/21087.htm" obj_spider = SpiderMain() obj_spider.craw(root_url)
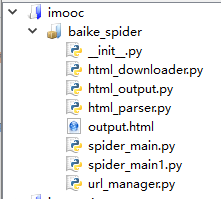
检查了半天,没发现问题啊。为啥还会报导入模块的错误嘞。






