parseFloat()与parseInt()的区别?
parseFloat()与parseInt()的区别?
parseFloat()与parseInt()的区别?
2016-05-11
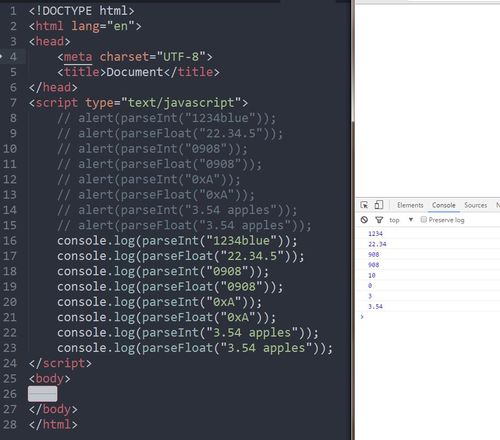
parseInt()方法首先查看位置0处的 字符,判断它是否是个有效数字;如果不是,该方法将返回NaN,不再继续执行其他操作。但如果该字符是有效数字,该方法将查看位置1处的字符,进行同样的 测试。这一过程将持续到发现非有效数字的字符为止,此时parseInt()将把该字符之前的字符串转换成数字。
例如
如果要把字符串 "1234blue "转换成整数,那么parseInt()将返回1234,因为当它检测到字符b时,就会停止检测过程。
parseInt()方法还有基模式,可以把二进制、八进制、十六进制或其他任何进制的字符串转换成整数。
基是由parseInt()方法的第二个参数指定的,所以要解析十六进制的值,当然,对二进制、八进制,甚至十进制(默认模式),都可以这样调用parseInt()方法。
如果十进制数包含前导0,那么最好采用基数10,这样才不会意外地得到八进制的值。
二、parseFloat()
与parseInt()方法的处理方式相似,从位置0开始查看每个字符,直到找到第一个非有效的字符为止,然后把该字符之前的字符串转换成数字。
不过,对于这个方法来说,第一个出现的小数点是有效字符。如果有两个小数点,第二个小数点将被看作无效的, parseFloat()方法会把这个小数点之前的字符串转换成数字。这意味着字符串 "22.34.5"将被解析成22.34。
使用parseFloat()方法的另一不同之处在于,字符串必须以十进制形式表示浮点数,而不能用八进制形式或十六进制形式。
该方法会忽略前导0,所以八进制数0908将被解析为908。对于十六进制数0xA,该方法将返回0,因为在浮点数中,x不是有效字符。
此外,parseFloat()没有基模式。
两者都是从位置0开始查看,直到非有效数字位置,再把有效的部分转成整数或者浮点数。
但是parseInt()可以带参数,指定二进制、八进制或者十六进制(默认十进制),可以解析八进制数如“010”、十六进制数“0x10”,而parseFloat()不带参数,不能解析八进制、十六进制数。
八进制数是以0开头,parseInt()对于有前导0的会解析成八进制数,而parseFloat()不会解析八进制数,因此八进制数都会被解析成10进制输出且输出时忽略前面的0
十六进制数是以0x开头,parseInt()会解析成十六进制数,而parseFloat()不会解析十六进制数,就跟“123db”这种类似,从头开始查看,到非有效数字位置为止,把前面的有效部分转成十进制,也就是说所有十六进制数都会被转成0。
另外,parseInt() parseFloat()对于"123db"这种可以部分转换,转成数字123,而Number()就会认为是NaN,因为整个字符串不能完整转化为数字。
在FF、Chrome、IE8、Opera下测试parseInt(“0xA”)均得到0,看书看到书上写的返回NaN,错啦……不过该书第二版已经做了更正哈哈。
举报

