课程
/后端开发
/Python
/Python开发简单爬虫
def parse(self, page_url, html_cont):
pass
2016-03-16
源自:Python开发简单爬虫 7-5
正在回答
视频引用的是2.7的python,在3.*里面大量写法全部改变了
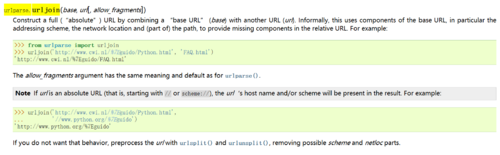
urljoin函数,哈哈 其实老师在视频里面都说的很清楚啦
终于懂了~_~
用help查看发现
JoshuaShang
问题在于urlparse.urljoin(page_url, new_url),是如何将当前爬取得url,和从这个url爬取出的新的不完整的url拼接起来的呢?
懂了,是spider_main中传入的url
mirrornighthehe 提问者
举报
本教程带您解开python爬虫这门神奇技术的面纱
购课补贴联系客服咨询优惠详情
慕课网APP您的移动学习伙伴
扫描二维码关注慕课网微信公众号